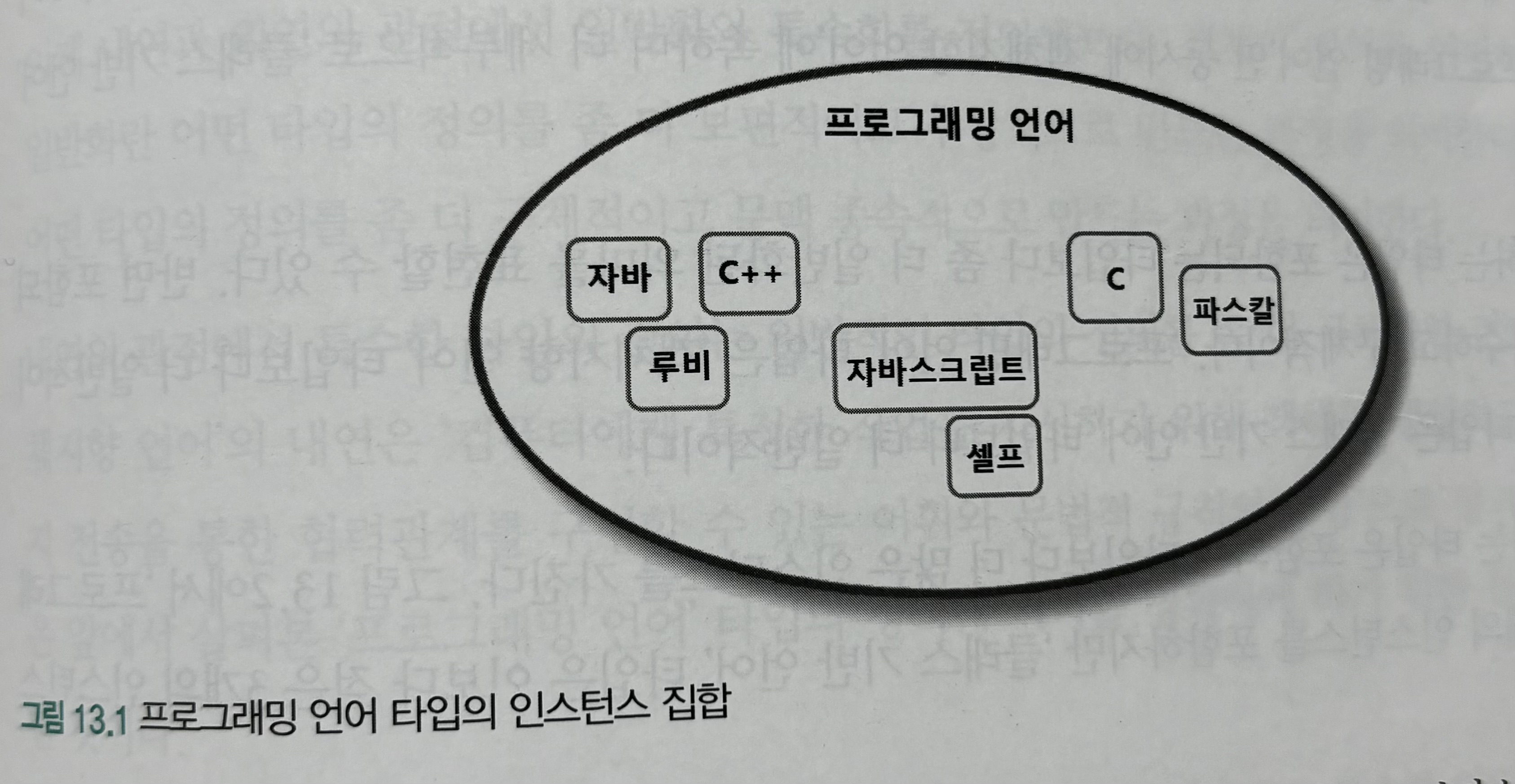
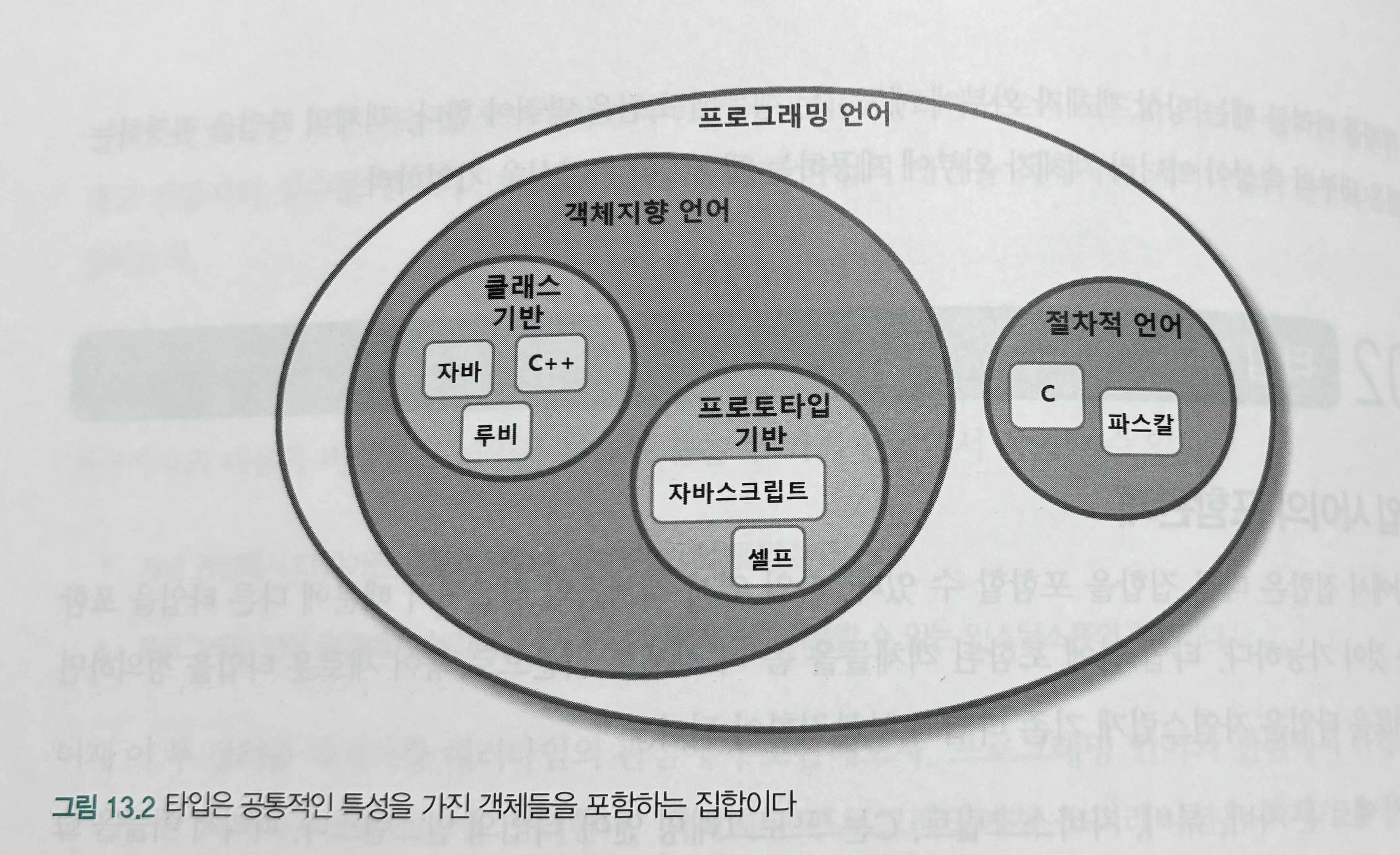
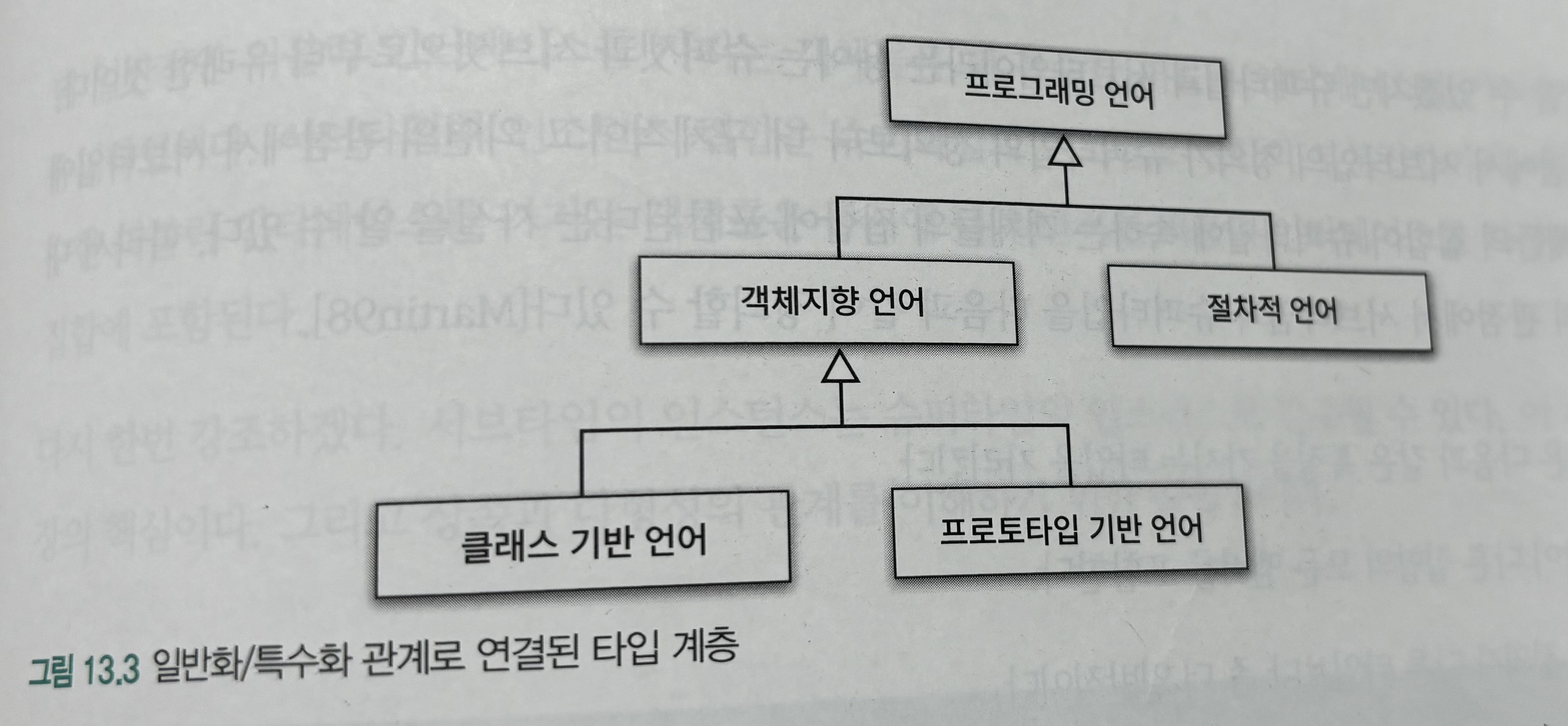
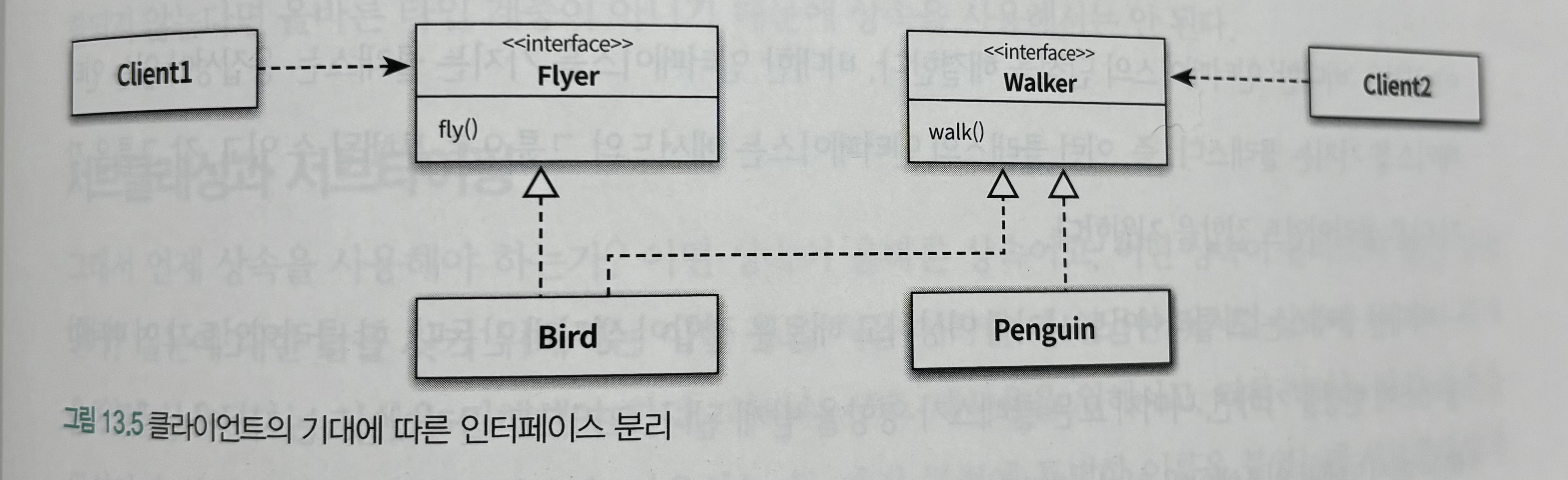
9. 데이터 파이프라인 구축하기
24 Jan 2024 | Kafka
9. 데이터 파이프라인 구축하기
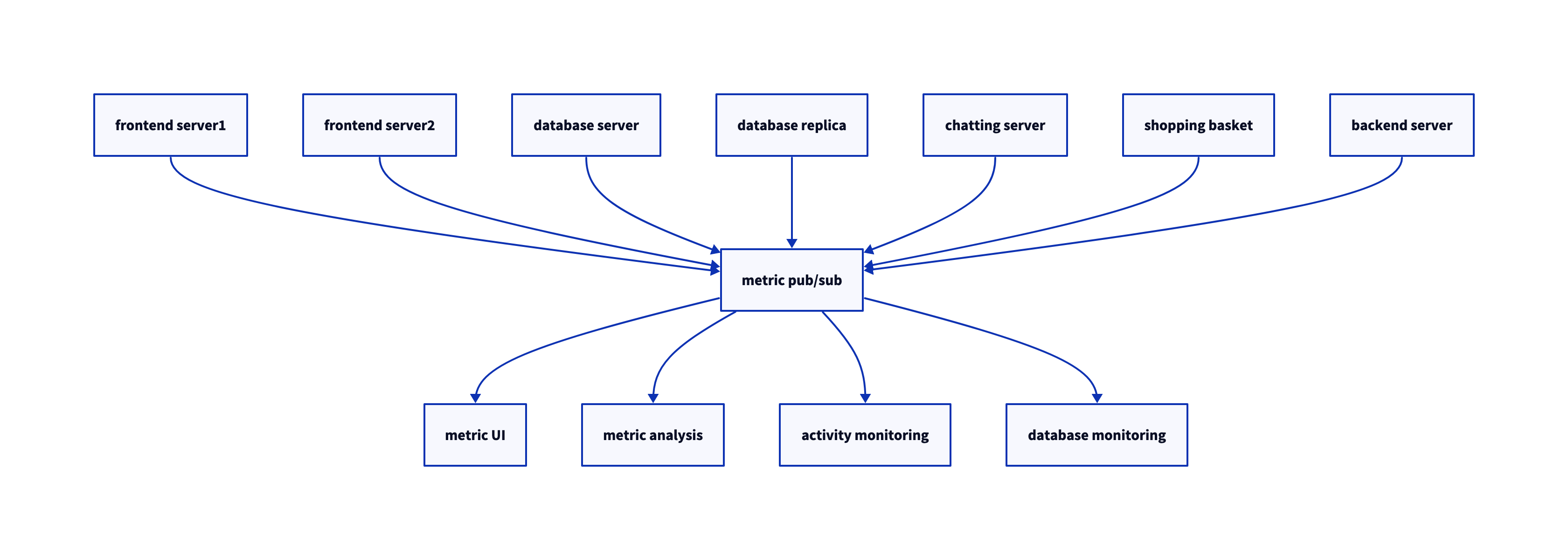
- 데이터 파이프라인에 있어서 카프카가 갖는 주요한 역할은 데이터 파이프라인의 다양한 단계 사이사이에 있어 매우 크고 안정적인 버퍼 역할을 해줄 수 있다는 점
- 데이터 파이프라인의 데이터를 쓰는 쪽과 읽는 쪽을 분리
- 하나의 원본에서 가져온 동일한 데이터를 서로 다른 적시성 timeliness과 가용성 요구 조건을 가진 여러 대상 애플리케이션이나 시스템으로 보낼 수 있게 함
- 파이프라인의 양쪽을 분리 -> 신뢰성, 보안성, 효율성 증대 -> 데이터 파이프라인에 적합
9.1 데이터 파이프라인 구축 시 고려 사항
9.1.1 적시성
- 좋은 데이터 통합 시스템은 각각의 데이터 파이프라인에 대해 서로 다른 적시성 요구 조건을 지원하면서도 업무에 대한 요구 조건이 변경되었을 때 이전하기 쉽다
- 카프카를 이해하는 좋은 방법은 쓰는 쪽과 읽는 쪽 사이의 시간적 민감도에 대한 요구 조건을 분리시키는 거대한 버퍼로 생각하는 것
- 백프레셔의 적용도 단순 -> 데이터의 소비 속도가 온전히 읽는 쪽에 의해 결정되므로, 카프카 자체에서 필요한 경우 쓰는 쪽에 대한 응답을 늦춤으로써 백프레셔를 적용
9.1.2 신뢰성
- 우리는 단일 장애점을 최대한 피하는 한편 모든 종류의 장애 발생에 대해 신속하고 자동화된 복구를 수행해야 함
- 또 다른 고려 사항은 전달 보장 delivery guarantee 이다.
- 대부분의 경우 최소 한 번 보장을 요구하는 것이 보통 -> 원본 시스템에서 발생한 이벤트가 모두 목적지에 도착해야 함
- ‘정확히 한 번’ 전달 보장을 요구하는 경우도 자주 볼 수 있음
- 카프카는 자체적으로 ‘최소 한 번’전달을 보장
- 트랜잭션 모델이나 고유 키를 지원하는 외부 데이터 저장소와 결합됐을 때 ‘정확히 한 번’까지도 보장 가능
- 많은 엔드포인트들이 ‘정확히 한 번’ 전달을 보장하는 데이터 저장소이므로 대체로 카프카 기반 데이터 파이프라인 역시 ‘정확히 한 번’ 전달 보장
- 카프카 커넥트 API가 오프셋을 다룰 때 외부 시스템과의 통합을 지원하는 API를 제공하기 때문에 커넥터 개발도 쉽다
9.1.3 높으면서도 조정 가능한 처리율
- 처리율이 갑자기 증가해야 하는 경우에도 적응할 수 있어야 함
- 카프카가 읽는 쪽과 쓰는 쪽의 버퍼 역할을 하므로, 더 이상 프로듀서의 처리율과 컨슈머의 처리율을 묶어서 생각하지 않아도 됨
- 프로듀서 처리율이 컨슈머 처리율을 넘어설 경우 데이터는 컨슈머가 따라잡을 때까지 카프카에 누적되므로, 복잡한 백프레셔 메커니즘 개발할 필요 없음
- 카프카는 독립적으로 프로듀서나 컨슈머를 추가하여 확장 가능 -> 요구 조건에 맞춰 파이프라인의 한쪽을 동적, 독립적으로 확장
9.1.4 데이터 형식
- 데이터 파이프라인에서 가장 중요하게 고려해야 할 것 중 하나 : 서로 다른 데이터 형식과 자료형을 적절히 사용
- 서로 다른 데이터베이스와 다른 저장 시스템마다 지원되는 자료형이 제각기 다름
- Avro 타입을 사용하여 XML이나 관계형 데이터를 카프카에 적재
- 엘라스틱 서치 : JSON
- HDFS : Parquet
- S3 : CSV
- 카프카와 커넥트 API는 데이터 형식에 완전히 독립적
9.1.5 변환
- 데이터 파이프라인을 구축하는 두가지 방식 : ETL, ELT
ETL (Extract-Transform-Load)
- 데이터 파이프라인이 통과하는 데이터에 변경을 가하는 작업까지도 담당
- 데이터를 수정한 뒤 다시 저장할 필요가 없어 시간과 공간 절약 가능
- 연산과 저장의 부담을 데이터 파이프라인으로 옮긴다는 특성이 장점/단점이 될 수 있다
- 누가 파이프라인에서 데이터 삭제를 일으키면, 사용처에서는 그걸 사용할수가 없다
ELT (Extract-Load-Transform)
- 데이터 파이프라인이 대상 시스템에 전달되는 데이터가 원본 데이터와 최대한 비슷하도록 (자료형 변환 정도) 최소한 변환만을 수행
- 대상 시스템에 ㅗ치대한의 유연성 제공
- 변환 작업이 대상 시스템의 CPU와 자원을 잡아먹는다
- 카프카 커넥트는 원본 시스템의 데이터를 카프카로 옮길 때 혹은 카프카의 데이터를 대상 시스템으로 옮길 때 단위 레코드를 변환할 수 있게 해주는 Single Message Transformation 기능 탑재
- 다른 토픽으로 메시지 보내기
- 필터링, 자료형 변환
- 특정한 필드 삭제
- Join, Aggreation과 같이 더 복잡한 변환 작업은 카프카 스트림으로 가능
9.1.6 보안
- 보안에 대해 고려해야하는 점
- 누가 카프카로 수집되는 데이터 접근가능?
- 파이프라인을 통과하는 데이터가 암호화 되었나?
- 누가 파이프라인을 변경가능한가?
- 접근이 제한된 곳의 데이터를 읽거나 써야할 경우, 인증 통과 가능한가?
- 개인 식별 정보 (Personally Identifiable Information, PII)를 저장, 접근, 사용할 때 법과 규제를 준수하는가?
- 카프카는 데이터 암호화 지원
- SASL을 이용한 인증/인가 지원
- 허가받거나 허가받지 않은 접근 내역에 대한 감사 로그 지원
- 외부 비밀 설정 지원 (ex, HashiCorp Vault)
9.1.7 장애 처리
- 모든 데이터가 항상 완벽할 것이라고 가정하는 것은 위험
- 모든 이벤트를 장기간에 걸쳐 저장하도록 카프카를 설정할 수 있기 때문에, 필요할 경우 이전 시점으로 돌아가서 에러르 ㄹ복구 가능
9.1.8 결합Coupling과 민첩성Agility
- 데이터 파이프라인을 구현할 때 중요한 것 중 하나는 데이터 원본과 대상을 분리할 수 있어야 함
- 의도치 않게 결합이 생기는 경우는 다음과 같음
임기응변Ad-hoc 파이프라인
- 어떤 기업이나 조직들은 애플리케이션을 연결해야 할 때마다 커스텀 파이프라인 구축 (Logstash, Flume, Informatica…)
- 이 경우 파이프라인이 특정 엔드포인트에 강하게 결합되어 설치, 유지 보수, 모니터링에 상당한 노력 필요
메타데이터 유실
- 만약 데이터 파이프라인이 스키마 메타데이터 보존x, 스키마 진화 지원x이면 소스와 싱크의 소프트웨어들이 강하게 결합됨
- 스키마 정보가 없으므로, 두 소프트웨어 모두 데이터 파싱/해석 방법을 알아야 함
과도한 처리
- 파이프라인에서 데이터 처리를 너무 많이 하면 하단에 있는 시스템들이 데이터 파이프라인을 구축할 때 어떤 필드를 보존할지, 어떻게 데이터를 집적할지, 등에 선택지가 별로 남지 않게 됨
- 하단 애플리케이션의 요구 조건이 자주 변경될 수 있는데, 그 때마다 데이터 파이프라인을 변경해야 하는 경우가 생긴다
- 가공되지 않은 raw 데이터를 가능한 한 건드리지 않은 채로 하단에 있는 애플리케이션으로 내려보내고 (Kafka Streams 포함), 데이터를 처리하고 집적하는 방법은 애플리케이션이 알아서 결정하게 하는 것이 좀 더 유연하다
9.2 카프카 커넥트 vs. 프로듀서/컨슈머
- 전통적인 프로듀서와 컨슈머를 사용하는 방법 vs 커넥트 API와 커넥터를 사용하는 방법
- 카프카 커넥트는 카프카를 직접 코드나 API를 작성하지 않았고, 변경도 할 수 없는 데이터 저장소에 연결시켜야 할 떄 쓴다
- 카프카 커넥트의 사용자들이 실제로 해 줘야 할 일은 설정 파일을 작성하는 것 뿐
- 연결하고자 하는 데이터 저장소의 커넥터가 아직 없다면, 카프카 클라이언트 또는 커넥트 API 둘 중 하나를 사용해서 애플리케이션 직접 작성 가능
- 커넥트 API를 사용하는 것이 여러 표준화된 관리 기능을 제공하여 편리하다
9.3 카프카 커넥트
- 커넥트는 카프카와 다른 데이터 저장소 사이에 확장성과 신뢰성을 가지면서 데이터를 주고받을 수 있는 수단 제공
- 커넥터 플러그인을 개발하고 실행하기 위한 API와 런타임 제공
- 커넥터 플러그인은 카프카 커넥트가 실행시키는 라이브러리, 데이터 이동 담당
- 커넥터는 여러 worker 프로세스들의 클러스터 형태로 실행됨
- 사용자는 워커에 커넥터 플러그인을 설치한 뒤 REST API를 사용해서 커넥터별 설정을 잡아 주거나 관리해주면 됨
- 커넥터는 대용량의 데이터 이동을 병렬화해서 처리하고 워커의 유휴 자원을 더 효율적으로 활용하기 위해 task를 추가로 실행
- 소스 커넥터 task는 원본 시스템으로부터 데이터를 읽어 와서 커넥트 자료 객체의 형태로 워커 프로세스에 전달만 해주면 됨
- 싱크 커넥트 task는 워커로부터 커넥트 자료 객체를 받아서 대상 시스템에 쓰는 작업을 담당
- 커넥트는 자료 객체를 카프카에 쓸 때 사용되는 형식으로 바꿀 수 있도록 convertor사용
- JSON, Avro, Protobuf, …
9.3.1 카프카 커넥트 실행하기
- 카프카 커넥트를 프로덕션 환경에서 사용할 경우, 카프카 브로커와는 별도의 서버에서 커넥트를 실행시켜야 함
- 카프카 커넥트 워커를 실행시키는 것은 브로커를 실행시키는 것과 매우 비슷
$ bin/connect-distributed.sh config/connect-distibuted.properties
- 커넥트 워커의 핵심 설정은 다음과 같다
bootstrap.servers
- 카프카 커넥트와 함께 장동하는 카프카 브로커의 목록
- 커넥터는 다른 곳의 데이터를 이 브로커로 전달 혹은 브로커에서 다른 시스템으로 전송
- 클러스터 내의 최소 3개 이상 권장
group.id
- 동일한 그룹 ID를 갖는 모든 워커들은 같은 커넥트 클러스터를 구성
plugin.path
- 카프카 커넥트는 커넥터, 컨버터, transformation, 비밀 제공자를 다운로드 받아서 플랫폼에 플러그인할 수 있음
- 카프카 커넥트에는 커넥터와 그 의존성들을 찾을 수 있는 디렉토리를 1개 이상 설정 가능
- 237p 참고
key.converter와 value.converter
- 카프카에 저장될 메시지의 키와 밸류 부분에 각각에 대해 컨버터를 설정해 줄 수 있음
- 기본값 아파치 카프카에 포함되어 있는
JSONConverter를 사용하는 JSON형식
AvroConverter, ProtobufConverter, JsonSchemaConverter 역시 사용 가능- 컨버터마다 설정할 수 있는 값이 따로 있음
rest.host.name과 rest.port
- 커넥터를 설정하거나 모니터링할 때는 카프카 커넥트의 REST API를 사용하는 것이 보통, REST API에 사용할 특정한 포트값을 할당 가능
- 다믐과 같이 REST API 호출하여 확인 가능
$ curl http://localhost:8083/
{"version":"3.0.0-SNAPSHOT", "commit":"faed88303akdf", "kafka_cluster_id":"pfkdIELWNDm8Rtl-vALDKdg"}%
- REST API의 기준 URL을 호출함으로써 현재 실행되고 있는 버전 확인 가능
$ curl http://localhost:8083/connector-plugins
[
{
"class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"type": "sink",
"version": "3.0.0-SNAPHOT"
},
...
]
- 아파키 카프카 본체만 실행시키고 있는 만큼 사용 가능한 커넥터는 파일 소스, 파일 싱크, 그리고 미러메이커 2.0에 포함된 커넥터 뿐
9.3.2 커넥터 예제: 파일 소스와 파일 싱크
- 분산 모드로 커넥트 워커 실행, 프로덕션 환경에서는 고가용성 보장을 위해 최소 두세 개의 프로세스를 실행시켜야 하겠지만, 여기서는 하나만…
$ bin/connect-distributed.sh config/connect-distributed.properties &
- 다음 차례는 파일 소스 시작, 예제로는 카프카 설정 파일을 읽어오도록 커넥터 설정
$ echo '{"name":"load-kafka-config", "config":{"connector.class":"FileSreamSource","file":"config/server.properties","topic":"kafka-config-topic"}}' | curl -X POST -d @- http://localhost:8083/connectors \
-H "Content-Type: application/json"
{
"name": "load-kafka-config",
"config": {
"connector.class": "FileStreamSource",
"file": "config/server.properties",
"topic": "kafka-config-topic",
"name": "load-kafka-config"
},
"tasks": [
{
"connector": "load-kafka-config",
"task": 0
}
],
"type": "source"
}
- 제대로 저장되었는지 확인
$ bin/kafka-console-consumer.sh --bootstrap-server=localhost:9002 \
--topic kafka-config-topic --from-beginning
- 제대로 했다면 240p 하단 결과를 볼 수 있음
- 이것은 config/server.properties 파일의 내용물이 커넥터에 의해 줄 단위로 JSON으로 변환된 뒤 kafka-config-topic 토ㅠ픽에 저장된 것
- JSON 컨버터는 레코드마다 스키마 정보를 포함시키는 것이 기본 작동
- 이 경우 그냥 String 타입의 열인 payload하나만 있을 뿐, 각 레코드는 파일 한 줄씩을 포함
- 이제 싱크 커넥터를 사용해서 토픽의 내용물을 파일로 내보내보자
- 이렇게 생성된 파일은 원본 server.properties와 완전히 동일할 것
- JSONConverter가 JSON 레코드를 텍스트 문자열로 원상복구 시킬 것이기 때문
$ echo 'P{"name":"dump-kafka-config", "config":
{"connector.class":"FileStreamSink","file":"copy-of-server-properties","topics":"kafka-config-topic"}}'
| curl -X POST -d @- http://localhost:8083/connectors --header "Content-Type:application/json"
{"name":"dump-kafka-config","config":
{"connector.class":"FileStreamSink","file":"copy-of-server-properties","topics":"kafka-config-topic","name":"dump-kafka-config"},"tasks":[]}
- 소스 쪽 설정과 다른 부분
- 클래스 이름이 이제
FileStreamSink
- file속성은 있지만 레코드를 읽어 올 파일이 아닌 레코드를 쓸 파일을 가리킴
- 토픽 하나를 지정하는 대신 topics를 지정
- 여기까지 잘 했다면 kafka-config-topic에 넣어 줬던 config/server.properties 파일과 완전히 동일한 copy-of-server-properties 파일이 생성되었을 것
- 커넥터를 삭제하려면 다음과 같이 한다
$ curl -X DELETE http://localhost:8083/connectors/dump-kafka-config
- 실제 프로덕션에서 쓰면 안됨… 241p 하단 참조
9.3.3 커넥터 예제: MySQL에서 Elasticsearch로 데이터 보내기
- p242~p249 참고
9.3.4 개별 메시지 변환
- 데이터를 복사하는 것은 그 자체로 유용하지만, 대개 ETL 파이프라인에는 변환 단계가 포함됨
- stateless 변환을 stateful한 스트림 처리와 구분하여 SMT(Single Message Transformation)이라고 부름
- SMT는 보통 코드를 작성할 필요 없이 수행 됨
- Join, Aggregation등은 카프카 스트림즈 사용 필요
- SMT 종류들
- Cast : 필드의 데이터 타입을 바꿈
- MaskField : 특정 필드의 내용물을 null로 채움, 민감한 정보나 개인 식별 정보를 제거할 때 유용
- Filter : 특정한 조건에 부합하는 모든 메시지를 제외하거나 포함
- Flatten : 중첩된 자료 구조를 편다. 각 밸류값의 경로 안에 있는 모든 필드의 이름을 이어분틴 것이 새 키 값이 됨
- HeaderFrom : 메시지에 포함되어 있는 필드를 헤더로 이동시키거나 복사
- InsertHeader : 각 메시지의 헤더에 정적인 무자열을 추가
- InsertField : 메시지에 새로운 필드를 추가해 넣는다. 오프셋과 같은 메타데이터에서 가져온 값일 수도 있고 정적인 값일 수도 있음
- RegexRouter : 정규식과 교체할 문자열을 사용해서 목적지 토픽의 이름을 바꿈
- ReplaceField : 메시지에 포함된 필드를 삭제하거나 이름을 변경
- TimestampConverter : 필드의 시간 형식을 바꿈
- TimestampRouter : 메시지에 포함된 타임스탬프 값을 기준으로 토픽 변경. 이것은 싱크 커넥터에서 특히나 유용, 타임스탬프 기준으로 저장된 특정 테이블의 파티션에 메시지를 복사해야 할 경우, 토픽 이름만으로 목적지 시스템의 데이터세트를 찾아야 하기 때문
- 참고 자료
- Twelve Days of SMT : 다양한 변환에 대한 상세한 예제
- 변환 기능 직접 개발하고 싶을 때
9.3.5 카프카 커넥트: 좀 더 자세히 알아보기
- 카프카 커넥트를 사용하려면 워커 클러스터를 실행시킨 뒤 커넥터를 생성하거나 삭제해주어야 함
- 각 시스템과 그들 사이의 상호작용에 대해 조금 더 자세히 살펴보자
1. 커넥터(connector)와 태스크(task)
- 커넥터 플러그인은 커넥터 API를 구현함. 이것은 커넥터와 태스크, 두 부분을 포함한다
커넥터
- 커넥터에서 몇 개의 태스크가 실행되어야 하는지 결정
- 데이터 복사 작업을 각 태스크에 어떻게 분할해 줄지 결정
- 워커로부터 태스크 설정을 얻어와서 태스크에 전달
태스크
- 태스크는 데이터를 실제로 카프카에 넣거나 가져오는 작업을 담당
- 모든 태스크는 워커로부터 컨텍스트를 받아서 초기화 됨
- 각 컨텍스트는 각 커넥터가 초기화될 때 필요한 정보를 갖고 있음
2. 워커
- 카프카 커넥트의 워커 프로세스는 커넥터와 태스크를 실행시키는 역할을 맡는 ‘컨테이너’ 프로세스라고 할 수 있음
- 워커 프로세스는 커넥터와 그 설정을 정의하는 HTTP요청 처리, 커넥트 설정을 내부 카프카 토픽에 저장, 커넥터와 태스크 실행, 적절한 설정값 전달
- 워커 프로세스가 크래시 날 경우, 다른 워커들이 이를 감지하여 커넥터와 태스크를 다른 워커로 재할당
- 새로운 워커가 커넥트 클러스터에 추가된다면 다른 워커들이 이것을 감지하여 부하 균형이 잡히도록 커넥터와 태스크를 할당
- 소스와 싱크 커넥터의 오프셋을 내부 카프카 토픽에 자동으로 커밋하는 작업과 태스크에서 에러가 발생할 경우, 재시도하는 작업도 담당
- 커텍터와 태스크는 데이터 통합에서 데이터 이동 단계를 맡음
- 워커는 REST API, 설정 관리, 신뢰성, 고가용성, 규모 확장성 그리고 부하 분산을 담당
- 위와 같은 관심사의 분리 (separation of concerns)야말로 고전적인 컨슈머/프로듀서 API가 아닌, 커넥트 API를 사용할 때의 주된 이점
- 고전적인 컨슈머/프로듀서를 사용해서 설정관리, 에러 처리, REST API, 모니터링, 배ㅗㅍ, 규모 확장 및 춧고, 장애 대응과 같은 기능을 구현할 경우 제대로 동작하게 만드려면 몇 달이 걸림
- 워커가 위와 같은 일을 알아서 처리해줌
3. 컨버터 및 커넥트 데이터 모델
- 카프카 커넥터 API에는 데이터 API가 포함되어 있음. 이 API는 데이터 객체와 이 객체의 구조를 나타내는 스키마 모두를 다룸
- ex) JDBC 소스 커넥터는 데이터베이스의 여리을 읽어온 뒤, 베이터 베이스에서 리턴된 열의 데이터 타입에 따라
ConnectSchema 객체를 생성
- 각각의 열에 대해, 우리는 해당 열의 이름과 저장된 값을 저장
- 모든 소스 커넥터는 이것과 비슷한 작업을 수행 -> 원본 시스템의 이벤트를 읽어와서
Schema, Value 순서쌍 생성
- 싱크 커넥터는 정확히 반대 작업을 수행
- 커넥트 워커가 데이터 객체를 카프카에 어떻게 써야하는가?
- 컨버터가 이곳에 사용됨 (현재 기본 데이터 타입, 바이트 배열, 문자열, Avro, JSON, 스키마 있는 JSON, Protobuf)
- 싱크 커넥터는 정확히 반대 방향의 처리
- 컨버터를 사용함으로써 커넥트 API는 커넥터 구현과는 무관하게, 카프카에 서로 다른 형식의 데이터를 저장할 수 있도록 해줌
- 사용 가능한 컨버터만 있다면, 어떤 커넥터도 레코드 형식에 상관 없이 사용 가능
4. 오프셋 관리
- 오프셋 관리는 워커 프로세스가 커넥터에 제공하는 편리한 기능 중 하나
- 커넥터는 어떤 데이터를 이미 처리했는지 알아야 함, 그리고 커넥터는 카프카가 제공하는 API를 사용해서 어느 이벤트가 이미 처리되었는지에 대한 정보를 유지 관리할 수 있음
- 소스 커넥터의 경우, 커넥터가 커넥트 워커에 리턴하는 레코드에는 논리적인 파티션과 오프셋이 포함됨
- 이것은 카프카의 파티션과 오프셋이 아니라 원본 시스템에서 필요로 하는 파티션과 오프셋 ex) 파일 소스의 경우, 파일이 파티션 역할; 파일 안의 줄 혹은 문자 위치가 오프셋 역할; JDBC의 경우 테이블이 파티션, 테이블 레코드의 ID나 타임스탬프가 오프셋 역할
- 소스 커넥터를 개발할 때 가장 중요한 것 중 하나는 원본 시스템의 데이터를 분할하고 오프셋을 추적하는 좋은 방법을 결정하는 것 -> 커넥터의 병렬성 수준이나 전달의 의미구조에 영향을 미칠 수 있음
- 소스 커넥터가 레코드들을 리턴하면, 우커는 이 레코드를 카프카 브로커로 보냄, 만약 브로커가 해당 레코드를 성공적으로 쓴 뒤 해당 요청에 대한 응답을 보내면, 그제서야 워커는 방금 전 카프카로 보낸 레코드에 대한 오프셋을 저장
- 이렇게 함으로써 커넥터는 재시작 혹은 크래시 발생 후에도 마지막으로 저장되었던 오프셋에서부터 이벤트를 처리할 수 있음
- 이 오프셋을 카프카 내부 토픽에 저장할 수도 있지만, 다른곳에 할 수도 있음
- 싱크 커넥터는 비슷한 과정을 정반대 순서로 실행
9.4 카프카 커넥트의 대안
9.4.1 다른 데이터 저장소를 위한 수집 프레임워크
- 하둡의 경우 플룸, 엘라스틱서치의 로그스태시, Fluentd 등이 있음
- 카프카를 중심으로 쓰고있다면 kafka connect를 쓰는것이 좋다면, 엘라스틱서치를 중점적으로 쓰고있다면 로그스태시 써라
9.4.2 GUI 기반 ETL 툴
- 인포매티카, Talend, Pentaho, Apache NiFi, StreamSets
- 이러한 시스템들의 주된 담점은 대개 복잡한 워크플로를 상정하고 개발 되었기에, 단순히 데이터 교환이 목적일 경우 다소 무겁고 복잡하다
9.4.3 스트림 프로세싱 프레임워크
- 대부분의 스트림 프로세싱 프레임워크는 카프카에서 이벤트를 읽어와서 다른 시스템에 쓰는 기능을 포함하고 있음
- 단 메시지 유실이나 오염과 같은 문제에 대응하기는 좀 어러울 수 있음
9.5 요약
- 커넥트 써라 최고다
9. 데이터 파이프라인 구축하기
- 데이터 파이프라인에 있어서 카프카가 갖는 주요한 역할은 데이터 파이프라인의 다양한 단계 사이사이에 있어 매우 크고 안정적인 버퍼 역할을 해줄 수 있다는 점
- 데이터 파이프라인의 데이터를 쓰는 쪽과 읽는 쪽을 분리
- 하나의 원본에서 가져온 동일한 데이터를 서로 다른 적시성 timeliness과 가용성 요구 조건을 가진 여러 대상 애플리케이션이나 시스템으로 보낼 수 있게 함
- 파이프라인의 양쪽을 분리 -> 신뢰성, 보안성, 효율성 증대 -> 데이터 파이프라인에 적합
9.1 데이터 파이프라인 구축 시 고려 사항
9.1.1 적시성
- 좋은 데이터 통합 시스템은 각각의 데이터 파이프라인에 대해 서로 다른 적시성 요구 조건을 지원하면서도 업무에 대한 요구 조건이 변경되었을 때 이전하기 쉽다
- 카프카를 이해하는 좋은 방법은 쓰는 쪽과 읽는 쪽 사이의 시간적 민감도에 대한 요구 조건을 분리시키는 거대한 버퍼로 생각하는 것
- 백프레셔의 적용도 단순 -> 데이터의 소비 속도가 온전히 읽는 쪽에 의해 결정되므로, 카프카 자체에서 필요한 경우 쓰는 쪽에 대한 응답을 늦춤으로써 백프레셔를 적용
9.1.2 신뢰성
- 우리는 단일 장애점을 최대한 피하는 한편 모든 종류의 장애 발생에 대해 신속하고 자동화된 복구를 수행해야 함
- 또 다른 고려 사항은 전달 보장 delivery guarantee 이다.
- 대부분의 경우 최소 한 번 보장을 요구하는 것이 보통 -> 원본 시스템에서 발생한 이벤트가 모두 목적지에 도착해야 함
- ‘정확히 한 번’ 전달 보장을 요구하는 경우도 자주 볼 수 있음
- 카프카는 자체적으로 ‘최소 한 번’전달을 보장
- 트랜잭션 모델이나 고유 키를 지원하는 외부 데이터 저장소와 결합됐을 때 ‘정확히 한 번’까지도 보장 가능
- 많은 엔드포인트들이 ‘정확히 한 번’ 전달을 보장하는 데이터 저장소이므로 대체로 카프카 기반 데이터 파이프라인 역시 ‘정확히 한 번’ 전달 보장
- 카프카 커넥트 API가 오프셋을 다룰 때 외부 시스템과의 통합을 지원하는 API를 제공하기 때문에 커넥터 개발도 쉽다
9.1.3 높으면서도 조정 가능한 처리율
- 처리율이 갑자기 증가해야 하는 경우에도 적응할 수 있어야 함
- 카프카가 읽는 쪽과 쓰는 쪽의 버퍼 역할을 하므로, 더 이상 프로듀서의 처리율과 컨슈머의 처리율을 묶어서 생각하지 않아도 됨
- 프로듀서 처리율이 컨슈머 처리율을 넘어설 경우 데이터는 컨슈머가 따라잡을 때까지 카프카에 누적되므로, 복잡한 백프레셔 메커니즘 개발할 필요 없음
- 카프카는 독립적으로 프로듀서나 컨슈머를 추가하여 확장 가능 -> 요구 조건에 맞춰 파이프라인의 한쪽을 동적, 독립적으로 확장
9.1.4 데이터 형식
- 데이터 파이프라인에서 가장 중요하게 고려해야 할 것 중 하나 : 서로 다른 데이터 형식과 자료형을 적절히 사용
- 서로 다른 데이터베이스와 다른 저장 시스템마다 지원되는 자료형이 제각기 다름
- Avro 타입을 사용하여 XML이나 관계형 데이터를 카프카에 적재
- 엘라스틱 서치 : JSON
- HDFS : Parquet
- S3 : CSV
- 카프카와 커넥트 API는 데이터 형식에 완전히 독립적
9.1.5 변환
- 데이터 파이프라인을 구축하는 두가지 방식 : ETL, ELT
ETL (Extract-Transform-Load)
- 데이터 파이프라인이 통과하는 데이터에 변경을 가하는 작업까지도 담당
- 데이터를 수정한 뒤 다시 저장할 필요가 없어 시간과 공간 절약 가능
- 연산과 저장의 부담을 데이터 파이프라인으로 옮긴다는 특성이 장점/단점이 될 수 있다
- 누가 파이프라인에서 데이터 삭제를 일으키면, 사용처에서는 그걸 사용할수가 없다
ELT (Extract-Load-Transform)
- 데이터 파이프라인이 대상 시스템에 전달되는 데이터가 원본 데이터와 최대한 비슷하도록 (자료형 변환 정도) 최소한 변환만을 수행
- 대상 시스템에 ㅗ치대한의 유연성 제공
- 변환 작업이 대상 시스템의 CPU와 자원을 잡아먹는다
- 카프카 커넥트는 원본 시스템의 데이터를 카프카로 옮길 때 혹은 카프카의 데이터를 대상 시스템으로 옮길 때 단위 레코드를 변환할 수 있게 해주는 Single Message Transformation 기능 탑재
- 다른 토픽으로 메시지 보내기
- 필터링, 자료형 변환
- 특정한 필드 삭제
- Join, Aggreation과 같이 더 복잡한 변환 작업은 카프카 스트림으로 가능
9.1.6 보안
- 보안에 대해 고려해야하는 점
- 누가 카프카로 수집되는 데이터 접근가능?
- 파이프라인을 통과하는 데이터가 암호화 되었나?
- 누가 파이프라인을 변경가능한가?
- 접근이 제한된 곳의 데이터를 읽거나 써야할 경우, 인증 통과 가능한가?
- 개인 식별 정보 (Personally Identifiable Information, PII)를 저장, 접근, 사용할 때 법과 규제를 준수하는가?
- 카프카는 데이터 암호화 지원
- SASL을 이용한 인증/인가 지원
- 허가받거나 허가받지 않은 접근 내역에 대한 감사 로그 지원
- 외부 비밀 설정 지원 (ex, HashiCorp Vault)
9.1.7 장애 처리
- 모든 데이터가 항상 완벽할 것이라고 가정하는 것은 위험
- 모든 이벤트를 장기간에 걸쳐 저장하도록 카프카를 설정할 수 있기 때문에, 필요할 경우 이전 시점으로 돌아가서 에러르 ㄹ복구 가능
9.1.8 결합Coupling과 민첩성Agility
- 데이터 파이프라인을 구현할 때 중요한 것 중 하나는 데이터 원본과 대상을 분리할 수 있어야 함
- 의도치 않게 결합이 생기는 경우는 다음과 같음
임기응변Ad-hoc 파이프라인
- 어떤 기업이나 조직들은 애플리케이션을 연결해야 할 때마다 커스텀 파이프라인 구축 (Logstash, Flume, Informatica…)
- 이 경우 파이프라인이 특정 엔드포인트에 강하게 결합되어 설치, 유지 보수, 모니터링에 상당한 노력 필요
메타데이터 유실
- 만약 데이터 파이프라인이 스키마 메타데이터 보존x, 스키마 진화 지원x이면 소스와 싱크의 소프트웨어들이 강하게 결합됨
- 스키마 정보가 없으므로, 두 소프트웨어 모두 데이터 파싱/해석 방법을 알아야 함
과도한 처리
- 파이프라인에서 데이터 처리를 너무 많이 하면 하단에 있는 시스템들이 데이터 파이프라인을 구축할 때 어떤 필드를 보존할지, 어떻게 데이터를 집적할지, 등에 선택지가 별로 남지 않게 됨
- 하단 애플리케이션의 요구 조건이 자주 변경될 수 있는데, 그 때마다 데이터 파이프라인을 변경해야 하는 경우가 생긴다
- 가공되지 않은 raw 데이터를 가능한 한 건드리지 않은 채로 하단에 있는 애플리케이션으로 내려보내고 (Kafka Streams 포함), 데이터를 처리하고 집적하는 방법은 애플리케이션이 알아서 결정하게 하는 것이 좀 더 유연하다
9.2 카프카 커넥트 vs. 프로듀서/컨슈머
- 전통적인 프로듀서와 컨슈머를 사용하는 방법 vs 커넥트 API와 커넥터를 사용하는 방법
- 카프카 커넥트는 카프카를 직접 코드나 API를 작성하지 않았고, 변경도 할 수 없는 데이터 저장소에 연결시켜야 할 떄 쓴다
- 카프카 커넥트의 사용자들이 실제로 해 줘야 할 일은 설정 파일을 작성하는 것 뿐
- 연결하고자 하는 데이터 저장소의 커넥터가 아직 없다면, 카프카 클라이언트 또는 커넥트 API 둘 중 하나를 사용해서 애플리케이션 직접 작성 가능
- 커넥트 API를 사용하는 것이 여러 표준화된 관리 기능을 제공하여 편리하다
9.3 카프카 커넥트
- 커넥트는 카프카와 다른 데이터 저장소 사이에 확장성과 신뢰성을 가지면서 데이터를 주고받을 수 있는 수단 제공
- 커넥터 플러그인을 개발하고 실행하기 위한 API와 런타임 제공
- 커넥터 플러그인은 카프카 커넥트가 실행시키는 라이브러리, 데이터 이동 담당
- 커넥터는 여러 worker 프로세스들의 클러스터 형태로 실행됨
- 사용자는 워커에 커넥터 플러그인을 설치한 뒤 REST API를 사용해서 커넥터별 설정을 잡아 주거나 관리해주면 됨
- 커넥터는 대용량의 데이터 이동을 병렬화해서 처리하고 워커의 유휴 자원을 더 효율적으로 활용하기 위해 task를 추가로 실행
- 소스 커넥터 task는 원본 시스템으로부터 데이터를 읽어 와서 커넥트 자료 객체의 형태로 워커 프로세스에 전달만 해주면 됨
- 싱크 커넥트 task는 워커로부터 커넥트 자료 객체를 받아서 대상 시스템에 쓰는 작업을 담당
- 커넥트는 자료 객체를 카프카에 쓸 때 사용되는 형식으로 바꿀 수 있도록 convertor사용
- JSON, Avro, Protobuf, …
9.3.1 카프카 커넥트 실행하기
- 카프카 커넥트를 프로덕션 환경에서 사용할 경우, 카프카 브로커와는 별도의 서버에서 커넥트를 실행시켜야 함
- 카프카 커넥트 워커를 실행시키는 것은 브로커를 실행시키는 것과 매우 비슷
$ bin/connect-distributed.sh config/connect-distibuted.properties
- 커넥트 워커의 핵심 설정은 다음과 같다
bootstrap.servers
- 카프카 커넥트와 함께 장동하는 카프카 브로커의 목록
- 커넥터는 다른 곳의 데이터를 이 브로커로 전달 혹은 브로커에서 다른 시스템으로 전송
- 클러스터 내의 최소 3개 이상 권장
group.id
- 동일한 그룹 ID를 갖는 모든 워커들은 같은 커넥트 클러스터를 구성
plugin.path
- 카프카 커넥트는 커넥터, 컨버터, transformation, 비밀 제공자를 다운로드 받아서 플랫폼에 플러그인할 수 있음
- 카프카 커넥트에는 커넥터와 그 의존성들을 찾을 수 있는 디렉토리를 1개 이상 설정 가능
- 237p 참고
key.converter와 value.converter
- 카프카에 저장될 메시지의 키와 밸류 부분에 각각에 대해 컨버터를 설정해 줄 수 있음
- 기본값 아파치 카프카에 포함되어 있는
JSONConverter를 사용하는 JSON형식 AvroConverter,ProtobufConverter,JsonSchemaConverter역시 사용 가능- 컨버터마다 설정할 수 있는 값이 따로 있음
rest.host.name과 rest.port
- 커넥터를 설정하거나 모니터링할 때는 카프카 커넥트의 REST API를 사용하는 것이 보통, REST API에 사용할 특정한 포트값을 할당 가능
- 다믐과 같이 REST API 호출하여 확인 가능
$ curl http://localhost:8083/
{"version":"3.0.0-SNAPSHOT", "commit":"faed88303akdf", "kafka_cluster_id":"pfkdIELWNDm8Rtl-vALDKdg"}%
- REST API의 기준 URL을 호출함으로써 현재 실행되고 있는 버전 확인 가능
$ curl http://localhost:8083/connector-plugins
[
{
"class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"type": "sink",
"version": "3.0.0-SNAPHOT"
},
...
]
- 아파키 카프카 본체만 실행시키고 있는 만큼 사용 가능한 커넥터는 파일 소스, 파일 싱크, 그리고 미러메이커 2.0에 포함된 커넥터 뿐
9.3.2 커넥터 예제: 파일 소스와 파일 싱크
- 분산 모드로 커넥트 워커 실행, 프로덕션 환경에서는 고가용성 보장을 위해 최소 두세 개의 프로세스를 실행시켜야 하겠지만, 여기서는 하나만…
$ bin/connect-distributed.sh config/connect-distributed.properties &
- 다음 차례는 파일 소스 시작, 예제로는 카프카 설정 파일을 읽어오도록 커넥터 설정
$ echo '{"name":"load-kafka-config", "config":{"connector.class":"FileSreamSource","file":"config/server.properties","topic":"kafka-config-topic"}}' | curl -X POST -d @- http://localhost:8083/connectors \
-H "Content-Type: application/json"
{
"name": "load-kafka-config",
"config": {
"connector.class": "FileStreamSource",
"file": "config/server.properties",
"topic": "kafka-config-topic",
"name": "load-kafka-config"
},
"tasks": [
{
"connector": "load-kafka-config",
"task": 0
}
],
"type": "source"
}
- 제대로 저장되었는지 확인
$ bin/kafka-console-consumer.sh --bootstrap-server=localhost:9002 \
--topic kafka-config-topic --from-beginning
- 제대로 했다면 240p 하단 결과를 볼 수 있음
- 이것은 config/server.properties 파일의 내용물이 커넥터에 의해 줄 단위로 JSON으로 변환된 뒤 kafka-config-topic 토ㅠ픽에 저장된 것
- JSON 컨버터는 레코드마다 스키마 정보를 포함시키는 것이 기본 작동
- 이 경우 그냥 String 타입의 열인 payload하나만 있을 뿐, 각 레코드는 파일 한 줄씩을 포함
- 이제 싱크 커넥터를 사용해서 토픽의 내용물을 파일로 내보내보자
- 이렇게 생성된 파일은 원본 server.properties와 완전히 동일할 것
- JSONConverter가 JSON 레코드를 텍스트 문자열로 원상복구 시킬 것이기 때문
$ echo 'P{"name":"dump-kafka-config", "config":
{"connector.class":"FileStreamSink","file":"copy-of-server-properties","topics":"kafka-config-topic"}}'
| curl -X POST -d @- http://localhost:8083/connectors --header "Content-Type:application/json"
{"name":"dump-kafka-config","config":
{"connector.class":"FileStreamSink","file":"copy-of-server-properties","topics":"kafka-config-topic","name":"dump-kafka-config"},"tasks":[]}
- 소스 쪽 설정과 다른 부분
- 클래스 이름이 이제
FileStreamSink - file속성은 있지만 레코드를 읽어 올 파일이 아닌 레코드를 쓸 파일을 가리킴
- 토픽 하나를 지정하는 대신 topics를 지정
- 클래스 이름이 이제
- 여기까지 잘 했다면 kafka-config-topic에 넣어 줬던 config/server.properties 파일과 완전히 동일한 copy-of-server-properties 파일이 생성되었을 것
- 커넥터를 삭제하려면 다음과 같이 한다
$ curl -X DELETE http://localhost:8083/connectors/dump-kafka-config
- 실제 프로덕션에서 쓰면 안됨… 241p 하단 참조
9.3.3 커넥터 예제: MySQL에서 Elasticsearch로 데이터 보내기
- p242~p249 참고
9.3.4 개별 메시지 변환
- 데이터를 복사하는 것은 그 자체로 유용하지만, 대개 ETL 파이프라인에는 변환 단계가 포함됨
- stateless 변환을 stateful한 스트림 처리와 구분하여 SMT(Single Message Transformation)이라고 부름
- SMT는 보통 코드를 작성할 필요 없이 수행 됨
- Join, Aggregation등은 카프카 스트림즈 사용 필요
- SMT 종류들
- Cast : 필드의 데이터 타입을 바꿈
- MaskField : 특정 필드의 내용물을 null로 채움, 민감한 정보나 개인 식별 정보를 제거할 때 유용
- Filter : 특정한 조건에 부합하는 모든 메시지를 제외하거나 포함
- Flatten : 중첩된 자료 구조를 편다. 각 밸류값의 경로 안에 있는 모든 필드의 이름을 이어분틴 것이 새 키 값이 됨
- HeaderFrom : 메시지에 포함되어 있는 필드를 헤더로 이동시키거나 복사
- InsertHeader : 각 메시지의 헤더에 정적인 무자열을 추가
- InsertField : 메시지에 새로운 필드를 추가해 넣는다. 오프셋과 같은 메타데이터에서 가져온 값일 수도 있고 정적인 값일 수도 있음
- RegexRouter : 정규식과 교체할 문자열을 사용해서 목적지 토픽의 이름을 바꿈
- ReplaceField : 메시지에 포함된 필드를 삭제하거나 이름을 변경
- TimestampConverter : 필드의 시간 형식을 바꿈
- TimestampRouter : 메시지에 포함된 타임스탬프 값을 기준으로 토픽 변경. 이것은 싱크 커넥터에서 특히나 유용, 타임스탬프 기준으로 저장된 특정 테이블의 파티션에 메시지를 복사해야 할 경우, 토픽 이름만으로 목적지 시스템의 데이터세트를 찾아야 하기 때문
- 참고 자료
- Twelve Days of SMT : 다양한 변환에 대한 상세한 예제
- 변환 기능 직접 개발하고 싶을 때
9.3.5 카프카 커넥트: 좀 더 자세히 알아보기
- 카프카 커넥트를 사용하려면 워커 클러스터를 실행시킨 뒤 커넥터를 생성하거나 삭제해주어야 함
- 각 시스템과 그들 사이의 상호작용에 대해 조금 더 자세히 살펴보자
1. 커넥터(connector)와 태스크(task)
- 커넥터 플러그인은 커넥터 API를 구현함. 이것은 커넥터와 태스크, 두 부분을 포함한다
커넥터
- 커넥터에서 몇 개의 태스크가 실행되어야 하는지 결정
- 데이터 복사 작업을 각 태스크에 어떻게 분할해 줄지 결정
- 워커로부터 태스크 설정을 얻어와서 태스크에 전달
태스크
- 태스크는 데이터를 실제로 카프카에 넣거나 가져오는 작업을 담당
- 모든 태스크는 워커로부터 컨텍스트를 받아서 초기화 됨
- 각 컨텍스트는 각 커넥터가 초기화될 때 필요한 정보를 갖고 있음
2. 워커
- 카프카 커넥트의 워커 프로세스는 커넥터와 태스크를 실행시키는 역할을 맡는 ‘컨테이너’ 프로세스라고 할 수 있음
- 워커 프로세스는 커넥터와 그 설정을 정의하는 HTTP요청 처리, 커넥트 설정을 내부 카프카 토픽에 저장, 커넥터와 태스크 실행, 적절한 설정값 전달
- 워커 프로세스가 크래시 날 경우, 다른 워커들이 이를 감지하여 커넥터와 태스크를 다른 워커로 재할당
- 새로운 워커가 커넥트 클러스터에 추가된다면 다른 워커들이 이것을 감지하여 부하 균형이 잡히도록 커넥터와 태스크를 할당
- 소스와 싱크 커넥터의 오프셋을 내부 카프카 토픽에 자동으로 커밋하는 작업과 태스크에서 에러가 발생할 경우, 재시도하는 작업도 담당
- 커텍터와 태스크는 데이터 통합에서 데이터 이동 단계를 맡음
- 워커는 REST API, 설정 관리, 신뢰성, 고가용성, 규모 확장성 그리고 부하 분산을 담당
- 위와 같은 관심사의 분리 (separation of concerns)야말로 고전적인 컨슈머/프로듀서 API가 아닌, 커넥트 API를 사용할 때의 주된 이점
- 고전적인 컨슈머/프로듀서를 사용해서 설정관리, 에러 처리, REST API, 모니터링, 배ㅗㅍ, 규모 확장 및 춧고, 장애 대응과 같은 기능을 구현할 경우 제대로 동작하게 만드려면 몇 달이 걸림
- 워커가 위와 같은 일을 알아서 처리해줌
3. 컨버터 및 커넥트 데이터 모델
- 카프카 커넥터 API에는 데이터 API가 포함되어 있음. 이 API는 데이터 객체와 이 객체의 구조를 나타내는 스키마 모두를 다룸
- ex) JDBC 소스 커넥터는 데이터베이스의 여리을 읽어온 뒤, 베이터 베이스에서 리턴된 열의 데이터 타입에 따라
ConnectSchema객체를 생성- 각각의 열에 대해, 우리는 해당 열의 이름과 저장된 값을 저장
- 모든 소스 커넥터는 이것과 비슷한 작업을 수행 -> 원본 시스템의 이벤트를 읽어와서
Schema, Value순서쌍 생성 - 싱크 커넥터는 정확히 반대 작업을 수행
- ex) JDBC 소스 커넥터는 데이터베이스의 여리을 읽어온 뒤, 베이터 베이스에서 리턴된 열의 데이터 타입에 따라
- 커넥트 워커가 데이터 객체를 카프카에 어떻게 써야하는가?
- 컨버터가 이곳에 사용됨 (현재 기본 데이터 타입, 바이트 배열, 문자열, Avro, JSON, 스키마 있는 JSON, Protobuf)
- 싱크 커넥터는 정확히 반대 방향의 처리
- 컨버터를 사용함으로써 커넥트 API는 커넥터 구현과는 무관하게, 카프카에 서로 다른 형식의 데이터를 저장할 수 있도록 해줌
- 사용 가능한 컨버터만 있다면, 어떤 커넥터도 레코드 형식에 상관 없이 사용 가능
4. 오프셋 관리
- 오프셋 관리는 워커 프로세스가 커넥터에 제공하는 편리한 기능 중 하나
- 커넥터는 어떤 데이터를 이미 처리했는지 알아야 함, 그리고 커넥터는 카프카가 제공하는 API를 사용해서 어느 이벤트가 이미 처리되었는지에 대한 정보를 유지 관리할 수 있음
- 소스 커넥터의 경우, 커넥터가 커넥트 워커에 리턴하는 레코드에는 논리적인 파티션과 오프셋이 포함됨
- 이것은 카프카의 파티션과 오프셋이 아니라 원본 시스템에서 필요로 하는 파티션과 오프셋 ex) 파일 소스의 경우, 파일이 파티션 역할; 파일 안의 줄 혹은 문자 위치가 오프셋 역할; JDBC의 경우 테이블이 파티션, 테이블 레코드의 ID나 타임스탬프가 오프셋 역할
- 소스 커넥터를 개발할 때 가장 중요한 것 중 하나는 원본 시스템의 데이터를 분할하고 오프셋을 추적하는 좋은 방법을 결정하는 것 -> 커넥터의 병렬성 수준이나 전달의 의미구조에 영향을 미칠 수 있음
- 소스 커넥터가 레코드들을 리턴하면, 우커는 이 레코드를 카프카 브로커로 보냄, 만약 브로커가 해당 레코드를 성공적으로 쓴 뒤 해당 요청에 대한 응답을 보내면, 그제서야 워커는 방금 전 카프카로 보낸 레코드에 대한 오프셋을 저장
- 이렇게 함으로써 커넥터는 재시작 혹은 크래시 발생 후에도 마지막으로 저장되었던 오프셋에서부터 이벤트를 처리할 수 있음
- 이 오프셋을 카프카 내부 토픽에 저장할 수도 있지만, 다른곳에 할 수도 있음
- 싱크 커넥터는 비슷한 과정을 정반대 순서로 실행
9.4 카프카 커넥트의 대안
9.4.1 다른 데이터 저장소를 위한 수집 프레임워크
- 하둡의 경우 플룸, 엘라스틱서치의 로그스태시, Fluentd 등이 있음
- 카프카를 중심으로 쓰고있다면 kafka connect를 쓰는것이 좋다면, 엘라스틱서치를 중점적으로 쓰고있다면 로그스태시 써라
9.4.2 GUI 기반 ETL 툴
- 인포매티카, Talend, Pentaho, Apache NiFi, StreamSets
- 이러한 시스템들의 주된 담점은 대개 복잡한 워크플로를 상정하고 개발 되었기에, 단순히 데이터 교환이 목적일 경우 다소 무겁고 복잡하다
9.4.3 스트림 프로세싱 프레임워크
- 대부분의 스트림 프로세싱 프레임워크는 카프카에서 이벤트를 읽어와서 다른 시스템에 쓰는 기능을 포함하고 있음
- 단 메시지 유실이나 오염과 같은 문제에 대응하기는 좀 어러울 수 있음
9.5 요약
- 커넥트 써라 최고다