
7. 코딩하는 동안 38~40
30 Jul 2023 | Progmatic Programmer
Topic 38. 우연에 맡기는 프로그래밍
- 지뢰를 찾는 병사처럼 개발자는 지뢰밭에서 일한다.
- 하루에도 수백 개가 넘는 함정에 우리가 빠지기를 기대리고 있다.
- 우리는 우연에 맡기는 프로그래밍, 곧 행운과 우연한 성공에 의존하는 프로그래밍을 하지 않아야 함
- 대신 “의도적으로 프로그래밍”해야 한다.
우연에 맡기는 프로그래밍 하기 (Anti-pattern)
예시 (개발자 프레드)
- 프레드는 정확한 검증없이 코드를 덧붙이는 작업을 몇 주간 하였다.
- 갑자기 프로그램이 잘 돌아가지 않음
- 몇 시간 동안 고치려고 노력했지만 원인을 찾을 수 없음
분석
- 왜 코드가 망가졌는지 프레드가 모르는 까닭은 애초에 코드가 왜 잘 돌아가는지는 몰랐기 때문이다.
- 프레드가 제한적으로 ‘테스트’를 했을 때에는 코드가 잘 돌아가는 것 처럼 보였지만, 그것은 단지 그때 운이 좋았기 때문
구현에서 생기는 우연
- 어떤 루틴을 잘못된 데이터를 가지고 호출했다고 해 보자.
- 그 루틴은 예상하지 못한 데이터에 특정한 방식으로 반응을 하고, 여러분은 그 반을을 기반으로 코드를 작성한다.
- 하지만 루틴을 만든 사람의 의도는 그 루틴이 그런 식으로 작동하는 것이 아니었다.
- 이상하게 코드를 짜서 우연히 동작을 하게 된다면 그것을 고치지 않으려고 할 가능성이 크다.
- 잘 작동하는 데 괜히 건드려서 일을 만들 필요가 있을까? 우리가 보기에는 그래야 할 이유가 몇 가지 있다.
- 정말로 제대로 돌아가는 게 아닐지도 모른다. 그저 돌아가는 듯이 보이는 것일 수도 있다.
- 여러분이 의존하는 조건이 단지 우연인 경우도 있다. 화면 해상도가 다른 경우나 CPU 코어가 더 많은 경우 들 다른 상황에서는 이상하게 작동할지도 모른다.
- 문서화 되지 않은 동작은 라이브러리의 다음 릴리스에서 변경될 수도 있다.
- 불필요한 추가 호출은 코드를 더 느리게 만든다.
- 추가로 호출한 루틴에 새로운 버그가 생길 수도 있다.
- 다른 사람이 호출할 코드를 작성하고 있다면 모듈화를 잘하는 것, 그리고 잘 문서화한 적은 수의 인터페이스 아래에 구현을 숨기는 것 같은 기본 원칙들이 모두 도움이 됨
- 다른 루틴을 호출할 때도 문서화된 동작에만 의존하라.
- 어떤 이유로든 그럴 수 없다면 추측을 문서로 상세히 남겨라
비슷하다고 괜찮을 리는 없다
- UTC 관련 썰, 책 참고
유령 패턴
- 우연히 생긴 패턴들을 연역적으로 생긴 것이라고 생각하지 마라
- ex. 러시아 국가 수반 패턴
- 가정하지 말라. 증명하라.
상황에서 생기는 우연
- 특정한 상황에서 빚어지는 우연도 있음
- 여러분이 짜는 코드가 GUI에서만 작동한다고 가정하고 있지 않은가?
- 언제나 한국어 또는 영어라고 가정하고 있지 않은가?
- 언제나 사용자가 글을 읽을 수 있다고 생각하는가?
- 현재 디렉터리에 쓸 수 있다는 것에 의존하고 있지 않은가?
- 어떤 환경 변수나 설정 파일이 미리 존재한다는 것은?
- 서버의 시간이 정확하다는 것은?
- 네트워크를 쓸 수 있고, 속도가 어느 정도 이상이라는 것에 의존하지는 않는가?
- 인터넷 검색으로 찾은 첫 번째 답에서 코드를 복사해 올 때 여러분과 동인한 상황이라고 확신하는가?
- 아니면 의미는 신경 쓰지 않고 그냥 따라 하는 화물 숭배 cargo cult 코드를 만들고 있나?
Tip 62. 우연에 맡기는 프로그래밍을 하지 말라.
암묵적인 가정
- 우연은 여러 단계에서 우리를 오도할 수 있다.
- 테스트가 특히 가짜 원인과 우연한 결과로 가득 찬 영역이다.
- X의 원인은 Y라고 가정하기는 쉽다. 하지만 가정하지 말라. 증명하라.
- 확고한 사실에 근거하지 않은 가정은 어떤 프로젝트에서든 재앙의 근원이 된다.
의도적으로 프로그래밍하기
- 언제나 여러분이 지금 무엇을 하고 있는지 알아야 한다.
- 더 경험이 적은 프로그래머에게 코드를 상세히 설명할 수 있는가? 그렇지 않다면 아마 우연에 기대고 있는 것일 터이다.
- 자신도 잘 모르는 코드를 만들지 말라. 완전히 파악하지 못한 애플리케이션을 빌드하거나, 이해하지 못한 기술을 사용하면 우연의 함정에 빠질 가능성이 높다. 이것이 왜 동작하는지 잘 모른다면 왜 실패하는지도 알 리가 없다.
- 계획을 세우고 그것을 바탕으로 진행하라. 머릿속에 있는 계획이든, 냅킨이나 화이프보드에 적어놓은 계획이든 상관없다.
- 신뢰할 수 있는 것에만 기대라. 가정에 의존하지 말라. 무언가를 신회할 수 있을지 판단하기 어렵다면 일단 최악의 상황을 가정하라.
- 가정을 기록으로 남겨라. 자신의 마음속에서 가정을 명확하게 하는 데 도움이 될 뿐더러, 다른 사람과 그에 대해 소통하는 데에도 도움이 된다.
- 코드뿐 아니라 여러분이 세운 가정도 테스트해 보아야 한다. 어떤 일이든 추측만 하지 말고 실제로 시험해 보라. 여러분의 가정을 시험할 수 있는 단정문을 작성하라. 가정이 맞았다면 코드를 더 이해하기 쉽게 만든 셈이고, 가정이 틀렸다면 일찍 발견했으니 운이 좋았다고 생각하라.
- 노력을 기울일 대상의 우선순위를 정하라. 중요한 것에 먼저 시간을 투자하라. 중요한 부분이 가장 어려운 부분이기도 한 경우가 많다. 기본이나 기반 구조가 제대로 되어 있지 않다면 현란한 부가 기능도 다 부질없다.
- 과거의 노예가 되지 말라. 기존 코드가 앞으로 짤 코드를 지배하도록 놓아두지 말라. 언제나 리팩터링 할 자세가 되어 있어야 한다. 이런 결정이 프로젝트 일정에 영햐을 줄지도 모른다. 그러니 필요한 변경을 하지 않을 경우의 비용보다 일정이 늦어져서 발생하는 비용이 적어야 한다는 것을 염두에 두어라.
Topic 39. 알고리즘의 속도
- 대문자 O 표기법 (Big-O notation) 사용
알고리즘을 추정한다는 말의 의미
- 대부분의 알고리즘은 가변적인 입력 데이터를 다룬다
- n개의 문자열 정렬하기
- m x n 행렬의 역행렬 만들기
- n비트 키를 이용해서 메시지 암호화하기 등
- 일반적으로 입력의 크기는 알고리즘에 영향을 줌
- 입력의 크기가 클수록 알고리즘의 수행 시간이 길어지거나 사용하는 메모리 양이 늘어난다
- 중요한 알고리즘은 대부분 선형적이지 않다
- 특히 몇몇 알고리즘은 증가 폭이 선형보다 훨씬 크다
대문자 O 표기법
-
다들 아시죠…?
- O(1) : 상수 (배열의 원소 접근, 단순 명령문)
- O(logn) : 로그 (이진 검색) 로그의 밑은 중요치 않다
- O(n) : 선형 (순차 검색)
- O(nlogn) : 선형보다는 좋지 않지만, 그래도 그렇게 많이 나쁘지는 않음. (퀵 정렬과 힙 정렬의 평균 수행 시간)
- O(n^2) : 제곱 (선택 정렬과 삽입 정렬)
- O(n^3) : 세제곱 (두 n x n 행렬의 곱)
- O(C^n) : 지수 (여행하는 외판원 문제, 집합 분할 문제)
상식으로 추정하기
단순 반복문
- 단순 반복문 하나가 1부터 n까지 돌아간다면 O(n)일 가능성이 크다
- ex: 소진 탐색, 배열에서 최댓값 찾기, 체크섬 생성하기 등
중첩 반복문
- 반복문 안에 또 반목문이 들어 있다면, 알고리즘은 O(m x n)이 된다. 이런 코드를 작성하면 보통 코딩 테스트에서 떨어진다
반씩 자르기
- 반복문을 돌 때마다 작업 대상의 수를 반으로 줄여 나가는 알고리즘
- ex: 정렬된 목록의 이진 검색, 이진 트리의 탐색, 정수의 2진수 표현에서 첫 번째 1인 비트를 찾는 문제
분할 정복 (divide and conquer)
- 입력 데이터를 둘로 나눠서 각각 돌립적으로 작업한 다음, 결과를 합치는 알고리즘
- ex: quick sort
조합적 (combinatoric)
- 알고리즘이 항목의 permutation을 다루기 시작하면 대부분의 경우 수행 시간은 걷잡을 수 없이 늘어남
- 난해 hard 하다고 분류되는 문제를 푸는 알고리즘이 대부분 여기에 속한다
- ex: 여행하는 외판원 문제, bin packing problem, partition problem
- 종종 한정된 도메인 안에서 수행 시간을 줄이기 위해 휴리스틱을 동원
실전에서의 알고리즘 속도
Tip 63. 사용하는 알고리즘의 차수를 추정하라
- O(n^2) 알고리즘이 있다면 분할 정복을 사용하여 O(nlogn)으로 줄일 수 없는지 시도해 보라
- 코드의 실행 시간이 얼마나 될지 또는 메모리를 얼마나 사용할지 확실하지 않다면 직접 실행해 보라
- 입력 데이터의 크기를 바꾸어가며 프로파일링 몇번 해보면 쉽게 감을 잡을 수 있다
- 실무에서는 다른 효과들 (ex: thrashing)이 발생하여 실행시간이 폭발적으로 증가 할 수도 있다
- 추정을 이미 했다 하더라도 실제 서비스에서 실제 데이터로 돌아가는 코드의 수행 시간만이 정말로 의미 있는 수치다
Tip 64. 여러분의 추정을 테스트하라
최고라고 언제나 최고는 아니다
- 가장 빠른 알고리즘이 언제나 가장 좋은 알고리즘은 아니다
- 성급한 최적화를 조심하라
연습 문제
연습 문제 28
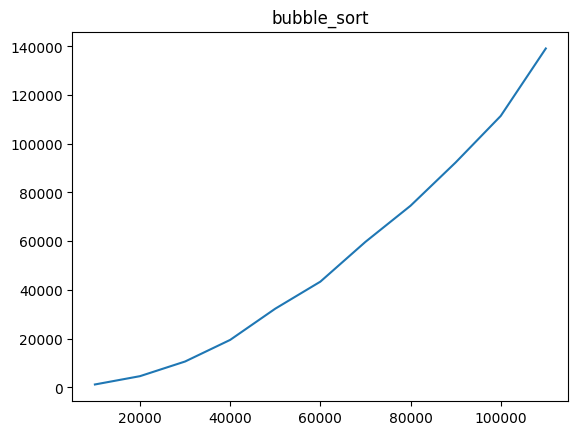
- 실행결과
Using Bubble Sort
10000, 1179
20000, 4592
30000, 10608
40000, 19484
50000, 32297
60000, 43393
70000, 59731
80000, 74558
90000, 92325
100000, 114256
110000, 139129
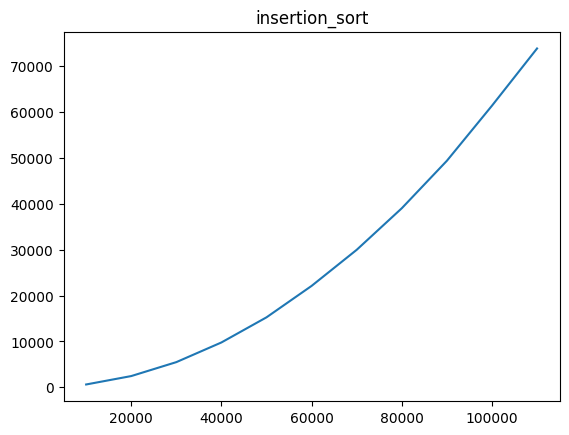
Using Insertion Sort
10000, 611
20000, 2445
30000, 5484
40000, 9772
50000, 15251
60000, 22104
70000, 29970
80000, 39033
90000, 49383
100000, 61391
110000, 73869
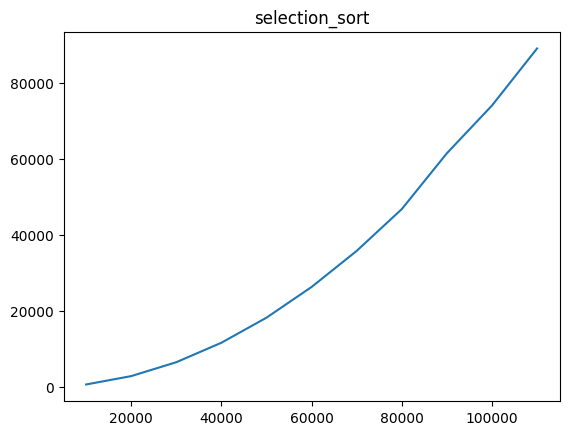
Using Selection Sort
10000, 729
20000, 2932
30000, 6584
40000, 11703
50000, 18292
60000, 26365
70000, 35840
80000, 46824
90000, 61504
100000, 74047
110000, 89045
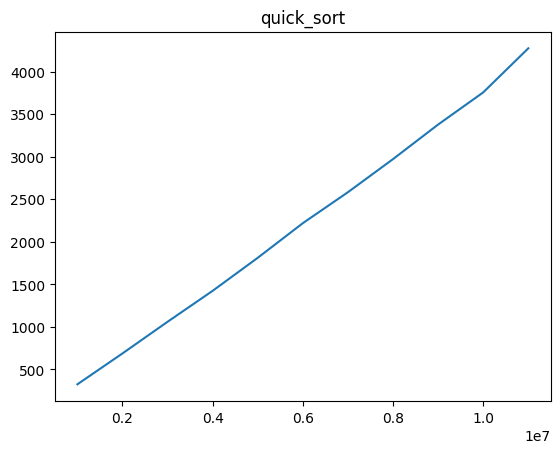
Using Quicksort
1000000, 324
2000000, 687
3000000, 1059
4000000, 1423
5000000, 1811
6000000, 2218
7000000, 2582
8000000, 2971
9000000, 3377
10000000, 3755
11000000, 4273
Topic 40. 리팩터링
이 천지 만물 모두 변하나… (H. F. 라이트)
- 프로그램이 발전함에 따라 점점 초기에 내린 결정을 다시 고려하고 코드의 일부분을 다시 작성할 일이 생긴다.
- 소프트웨어의 비유로 가장 널리 쓰이는 메타포는 건축 이지만, 저자는 조경에 비하고 싶다.
- 어떤 루틴이 너무 크게 자라거나 너무 많은 것을 하려고 한다면 둘로 나눠야 한다
- 계획한 대로 잘 되지 않는 것들은 잡초 제거하듯 뽑아내거나 가지치기를 해야 한다
밖으로 드러나는 동작은 그래도 유지한 채 내부 구조를 변경함으로써 이미 존재하는 코드를 재구성하는 체계적 기법 (마틴 파울러 - 리팩터링)
- 이 활동은 체계적이다. 아무렇게나 하는 것이 아니다
- 밖으로 드러나는 동작은 바뀌지 않는다. 기능을 추가하는 작업이 아니다
- 밖으로 드러나는 동작이 바뀌지 않는다는 것을 보장하려면 코드의 동작을 검증하는 좋은 자동화된 단위 테스트가 필요하다
리팩터링은 언제 하는가?
- 리팩터링은 여러분이 무언가를 알게 되었을 때 한다. 여러분이 작년이나 어제, 심지어 10분 전과 비겨ㅛ해서 더 많이 알게 되었다면, 리팩터링을 한다.
중복
- DRY 원칙 위반을 발견했다.
직교적이지 않은 설계
- 더 직교적으로 바꿀 수 있는 무언가를 발견했다.
더 이상 유효하지 않은 지식
- 사물은 변하고, 요구 사항은 병경되며, 지금 처리하고 있는 문제에 대한 여러분의 지식은 점점 늘어난다.
- 코드는 지금 상화엥 뒤떨어지지 않아야 한다.
사용 사례
- 진짜 사람들이 실제 상황에서 시스템을 사용하게 되면, 여러분은 어떤 기능은 예전에 생각했던 것보다 더 중요하고, 꼭 필요하다고 생각했던 기능은 그렇지 않은 경우도 있다는 것을 깨닫게 될 것이다.
성능
- 성능을 개선하려면 시스템의 한 영역에서 다른 영역으로 기능을 옮겨야 한다.
테스트 통과
- 여러분이 코드를 조금 추가한 후 추가한 테스트를 통과했을 때가, 방금 추가한 코드로 다시 뛰어들어 깔끔하게 정리하기에 최고의 타이밍
고통 관리
- 현실을 피하지 말자
- 소스 코드를 이곳저곳 변경하는 것은 굉장히 고통스러운 작업이다 (단위테스트가 잘 되어있다면 그렇게 고통스럽진 않다!)
- 많은 개발자들이 코드에 조금 개선할 부분이 있다는 이유만으로는 다시 돌아가서 코드 열기를 주저한다.
현실 세계의 복잡한 문제들
- 고객한테 리팩터링 해야하니까 1주일 더 달라고 하는 것은 할 수 없다
- 하지만 리팩터링의 타이밍을 놓치면 더 고통스러워 진다.
Tip 65. 일찍 리팩터링하고, 자주 리팩터링하라.
리팩터링은 어떻게 하는가?
- 리팩터링의 본질을 재설계다
마틴 파울러의 조언
- 리팩터링과 기능 추가를 동시에 하지 말라
- 리팩터링을 시작하기 전 든든한 테스트가 있는지 먼저 확인하라. 할 수 있는 한 자주 테스트를 돌려 보라. 망가진 것을 빠르게 알아챌 수 있다.
- 단계를 작게 나누어서 신중하게 작업하라. 단계를 작게 나누고, 한 단계가 끝날 때마다 테스트를 돌린다면 기나긴 디버깅 작업을 피할 수 있다.
Topic 38. 우연에 맡기는 프로그래밍
- 지뢰를 찾는 병사처럼 개발자는 지뢰밭에서 일한다.
- 하루에도 수백 개가 넘는 함정에 우리가 빠지기를 기대리고 있다.
- 우리는 우연에 맡기는 프로그래밍, 곧 행운과 우연한 성공에 의존하는 프로그래밍을 하지 않아야 함
- 대신 “의도적으로 프로그래밍”해야 한다.
우연에 맡기는 프로그래밍 하기 (Anti-pattern)
예시 (개발자 프레드)
- 프레드는 정확한 검증없이 코드를 덧붙이는 작업을 몇 주간 하였다.
- 갑자기 프로그램이 잘 돌아가지 않음
- 몇 시간 동안 고치려고 노력했지만 원인을 찾을 수 없음
분석
- 왜 코드가 망가졌는지 프레드가 모르는 까닭은 애초에 코드가 왜 잘 돌아가는지는 몰랐기 때문이다.
- 프레드가 제한적으로 ‘테스트’를 했을 때에는 코드가 잘 돌아가는 것 처럼 보였지만, 그것은 단지 그때 운이 좋았기 때문
구현에서 생기는 우연
- 어떤 루틴을 잘못된 데이터를 가지고 호출했다고 해 보자.
- 그 루틴은 예상하지 못한 데이터에 특정한 방식으로 반응을 하고, 여러분은 그 반을을 기반으로 코드를 작성한다.
- 하지만 루틴을 만든 사람의 의도는 그 루틴이 그런 식으로 작동하는 것이 아니었다.
- 이상하게 코드를 짜서 우연히 동작을 하게 된다면 그것을 고치지 않으려고 할 가능성이 크다.
- 잘 작동하는 데 괜히 건드려서 일을 만들 필요가 있을까? 우리가 보기에는 그래야 할 이유가 몇 가지 있다.
- 정말로 제대로 돌아가는 게 아닐지도 모른다. 그저 돌아가는 듯이 보이는 것일 수도 있다.
- 여러분이 의존하는 조건이 단지 우연인 경우도 있다. 화면 해상도가 다른 경우나 CPU 코어가 더 많은 경우 들 다른 상황에서는 이상하게 작동할지도 모른다.
- 문서화 되지 않은 동작은 라이브러리의 다음 릴리스에서 변경될 수도 있다.
- 불필요한 추가 호출은 코드를 더 느리게 만든다.
- 추가로 호출한 루틴에 새로운 버그가 생길 수도 있다.
- 다른 사람이 호출할 코드를 작성하고 있다면 모듈화를 잘하는 것, 그리고 잘 문서화한 적은 수의 인터페이스 아래에 구현을 숨기는 것 같은 기본 원칙들이 모두 도움이 됨
- 다른 루틴을 호출할 때도 문서화된 동작에만 의존하라.
- 어떤 이유로든 그럴 수 없다면 추측을 문서로 상세히 남겨라
비슷하다고 괜찮을 리는 없다
- UTC 관련 썰, 책 참고
유령 패턴
- 우연히 생긴 패턴들을 연역적으로 생긴 것이라고 생각하지 마라
- ex. 러시아 국가 수반 패턴
- 가정하지 말라. 증명하라.
상황에서 생기는 우연
- 특정한 상황에서 빚어지는 우연도 있음
- 여러분이 짜는 코드가 GUI에서만 작동한다고 가정하고 있지 않은가?
- 언제나 한국어 또는 영어라고 가정하고 있지 않은가?
- 언제나 사용자가 글을 읽을 수 있다고 생각하는가?
- 현재 디렉터리에 쓸 수 있다는 것에 의존하고 있지 않은가?
- 어떤 환경 변수나 설정 파일이 미리 존재한다는 것은?
- 서버의 시간이 정확하다는 것은?
- 네트워크를 쓸 수 있고, 속도가 어느 정도 이상이라는 것에 의존하지는 않는가?
- 인터넷 검색으로 찾은 첫 번째 답에서 코드를 복사해 올 때 여러분과 동인한 상황이라고 확신하는가?
- 아니면 의미는 신경 쓰지 않고 그냥 따라 하는 화물 숭배 cargo cult 코드를 만들고 있나?
Tip 62. 우연에 맡기는 프로그래밍을 하지 말라.
암묵적인 가정
- 우연은 여러 단계에서 우리를 오도할 수 있다.
- 테스트가 특히 가짜 원인과 우연한 결과로 가득 찬 영역이다.
- X의 원인은 Y라고 가정하기는 쉽다. 하지만 가정하지 말라. 증명하라.
- 확고한 사실에 근거하지 않은 가정은 어떤 프로젝트에서든 재앙의 근원이 된다.
의도적으로 프로그래밍하기
- 언제나 여러분이 지금 무엇을 하고 있는지 알아야 한다.
- 더 경험이 적은 프로그래머에게 코드를 상세히 설명할 수 있는가? 그렇지 않다면 아마 우연에 기대고 있는 것일 터이다.
- 자신도 잘 모르는 코드를 만들지 말라. 완전히 파악하지 못한 애플리케이션을 빌드하거나, 이해하지 못한 기술을 사용하면 우연의 함정에 빠질 가능성이 높다. 이것이 왜 동작하는지 잘 모른다면 왜 실패하는지도 알 리가 없다.
- 계획을 세우고 그것을 바탕으로 진행하라. 머릿속에 있는 계획이든, 냅킨이나 화이프보드에 적어놓은 계획이든 상관없다.
- 신뢰할 수 있는 것에만 기대라. 가정에 의존하지 말라. 무언가를 신회할 수 있을지 판단하기 어렵다면 일단 최악의 상황을 가정하라.
- 가정을 기록으로 남겨라. 자신의 마음속에서 가정을 명확하게 하는 데 도움이 될 뿐더러, 다른 사람과 그에 대해 소통하는 데에도 도움이 된다.
- 코드뿐 아니라 여러분이 세운 가정도 테스트해 보아야 한다. 어떤 일이든 추측만 하지 말고 실제로 시험해 보라. 여러분의 가정을 시험할 수 있는 단정문을 작성하라. 가정이 맞았다면 코드를 더 이해하기 쉽게 만든 셈이고, 가정이 틀렸다면 일찍 발견했으니 운이 좋았다고 생각하라.
- 노력을 기울일 대상의 우선순위를 정하라. 중요한 것에 먼저 시간을 투자하라. 중요한 부분이 가장 어려운 부분이기도 한 경우가 많다. 기본이나 기반 구조가 제대로 되어 있지 않다면 현란한 부가 기능도 다 부질없다.
- 과거의 노예가 되지 말라. 기존 코드가 앞으로 짤 코드를 지배하도록 놓아두지 말라. 언제나 리팩터링 할 자세가 되어 있어야 한다. 이런 결정이 프로젝트 일정에 영햐을 줄지도 모른다. 그러니 필요한 변경을 하지 않을 경우의 비용보다 일정이 늦어져서 발생하는 비용이 적어야 한다는 것을 염두에 두어라.
Topic 39. 알고리즘의 속도
- 대문자 O 표기법 (Big-O notation) 사용
알고리즘을 추정한다는 말의 의미
- 대부분의 알고리즘은 가변적인 입력 데이터를 다룬다
- n개의 문자열 정렬하기
- m x n 행렬의 역행렬 만들기
- n비트 키를 이용해서 메시지 암호화하기 등
- 일반적으로 입력의 크기는 알고리즘에 영향을 줌
- 입력의 크기가 클수록 알고리즘의 수행 시간이 길어지거나 사용하는 메모리 양이 늘어난다
- 중요한 알고리즘은 대부분 선형적이지 않다
- 특히 몇몇 알고리즘은 증가 폭이 선형보다 훨씬 크다
대문자 O 표기법
-
다들 아시죠…?
- O(1) : 상수 (배열의 원소 접근, 단순 명령문)
- O(logn) : 로그 (이진 검색) 로그의 밑은 중요치 않다
- O(n) : 선형 (순차 검색)
- O(nlogn) : 선형보다는 좋지 않지만, 그래도 그렇게 많이 나쁘지는 않음. (퀵 정렬과 힙 정렬의 평균 수행 시간)
- O(n^2) : 제곱 (선택 정렬과 삽입 정렬)
- O(n^3) : 세제곱 (두 n x n 행렬의 곱)
- O(C^n) : 지수 (여행하는 외판원 문제, 집합 분할 문제)
상식으로 추정하기
단순 반복문
- 단순 반복문 하나가 1부터 n까지 돌아간다면 O(n)일 가능성이 크다
- ex: 소진 탐색, 배열에서 최댓값 찾기, 체크섬 생성하기 등
중첩 반복문
- 반복문 안에 또 반목문이 들어 있다면, 알고리즘은 O(m x n)이 된다. 이런 코드를 작성하면 보통 코딩 테스트에서 떨어진다
반씩 자르기
- 반복문을 돌 때마다 작업 대상의 수를 반으로 줄여 나가는 알고리즘
- ex: 정렬된 목록의 이진 검색, 이진 트리의 탐색, 정수의 2진수 표현에서 첫 번째 1인 비트를 찾는 문제
분할 정복 (divide and conquer)
- 입력 데이터를 둘로 나눠서 각각 돌립적으로 작업한 다음, 결과를 합치는 알고리즘
- ex: quick sort
조합적 (combinatoric)
- 알고리즘이 항목의 permutation을 다루기 시작하면 대부분의 경우 수행 시간은 걷잡을 수 없이 늘어남
- 난해 hard 하다고 분류되는 문제를 푸는 알고리즘이 대부분 여기에 속한다
- ex: 여행하는 외판원 문제, bin packing problem, partition problem
- 종종 한정된 도메인 안에서 수행 시간을 줄이기 위해 휴리스틱을 동원
실전에서의 알고리즘 속도
Tip 63. 사용하는 알고리즘의 차수를 추정하라
- O(n^2) 알고리즘이 있다면 분할 정복을 사용하여 O(nlogn)으로 줄일 수 없는지 시도해 보라
- 코드의 실행 시간이 얼마나 될지 또는 메모리를 얼마나 사용할지 확실하지 않다면 직접 실행해 보라
- 입력 데이터의 크기를 바꾸어가며 프로파일링 몇번 해보면 쉽게 감을 잡을 수 있다
- 실무에서는 다른 효과들 (ex: thrashing)이 발생하여 실행시간이 폭발적으로 증가 할 수도 있다
- 추정을 이미 했다 하더라도 실제 서비스에서 실제 데이터로 돌아가는 코드의 수행 시간만이 정말로 의미 있는 수치다
Tip 64. 여러분의 추정을 테스트하라
최고라고 언제나 최고는 아니다
- 가장 빠른 알고리즘이 언제나 가장 좋은 알고리즘은 아니다
- 성급한 최적화를 조심하라
연습 문제
연습 문제 28
- 실행결과
Using Bubble Sort
10000, 1179
20000, 4592
30000, 10608
40000, 19484
50000, 32297
60000, 43393
70000, 59731
80000, 74558
90000, 92325
100000, 114256
110000, 139129
Using Insertion Sort
10000, 611
20000, 2445
30000, 5484
40000, 9772
50000, 15251
60000, 22104
70000, 29970
80000, 39033
90000, 49383
100000, 61391
110000, 73869
Using Selection Sort
10000, 729
20000, 2932
30000, 6584
40000, 11703
50000, 18292
60000, 26365
70000, 35840
80000, 46824
90000, 61504
100000, 74047
110000, 89045
Using Quicksort
1000000, 324
2000000, 687
3000000, 1059
4000000, 1423
5000000, 1811
6000000, 2218
7000000, 2582
8000000, 2971
9000000, 3377
10000000, 3755
11000000, 4273
Topic 40. 리팩터링
이 천지 만물 모두 변하나… (H. F. 라이트)
- 프로그램이 발전함에 따라 점점 초기에 내린 결정을 다시 고려하고 코드의 일부분을 다시 작성할 일이 생긴다.
- 소프트웨어의 비유로 가장 널리 쓰이는 메타포는 건축 이지만, 저자는 조경에 비하고 싶다.
- 어떤 루틴이 너무 크게 자라거나 너무 많은 것을 하려고 한다면 둘로 나눠야 한다
- 계획한 대로 잘 되지 않는 것들은 잡초 제거하듯 뽑아내거나 가지치기를 해야 한다
밖으로 드러나는 동작은 그래도 유지한 채 내부 구조를 변경함으로써 이미 존재하는 코드를 재구성하는 체계적 기법 (마틴 파울러 - 리팩터링)
- 이 활동은 체계적이다. 아무렇게나 하는 것이 아니다
- 밖으로 드러나는 동작은 바뀌지 않는다. 기능을 추가하는 작업이 아니다
- 밖으로 드러나는 동작이 바뀌지 않는다는 것을 보장하려면 코드의 동작을 검증하는 좋은 자동화된 단위 테스트가 필요하다
리팩터링은 언제 하는가?
- 리팩터링은 여러분이 무언가를 알게 되었을 때 한다. 여러분이 작년이나 어제, 심지어 10분 전과 비겨ㅛ해서 더 많이 알게 되었다면, 리팩터링을 한다.
중복
- DRY 원칙 위반을 발견했다.
직교적이지 않은 설계
- 더 직교적으로 바꿀 수 있는 무언가를 발견했다.
더 이상 유효하지 않은 지식
- 사물은 변하고, 요구 사항은 병경되며, 지금 처리하고 있는 문제에 대한 여러분의 지식은 점점 늘어난다.
- 코드는 지금 상화엥 뒤떨어지지 않아야 한다.
사용 사례
- 진짜 사람들이 실제 상황에서 시스템을 사용하게 되면, 여러분은 어떤 기능은 예전에 생각했던 것보다 더 중요하고, 꼭 필요하다고 생각했던 기능은 그렇지 않은 경우도 있다는 것을 깨닫게 될 것이다.
성능
- 성능을 개선하려면 시스템의 한 영역에서 다른 영역으로 기능을 옮겨야 한다.
테스트 통과
- 여러분이 코드를 조금 추가한 후 추가한 테스트를 통과했을 때가, 방금 추가한 코드로 다시 뛰어들어 깔끔하게 정리하기에 최고의 타이밍
고통 관리
- 현실을 피하지 말자
- 소스 코드를 이곳저곳 변경하는 것은 굉장히 고통스러운 작업이다 (단위테스트가 잘 되어있다면 그렇게 고통스럽진 않다!)
- 많은 개발자들이 코드에 조금 개선할 부분이 있다는 이유만으로는 다시 돌아가서 코드 열기를 주저한다.
현실 세계의 복잡한 문제들
- 고객한테 리팩터링 해야하니까 1주일 더 달라고 하는 것은 할 수 없다
- 하지만 리팩터링의 타이밍을 놓치면 더 고통스러워 진다.
Tip 65. 일찍 리팩터링하고, 자주 리팩터링하라.
리팩터링은 어떻게 하는가?
- 리팩터링의 본질을 재설계다
마틴 파울러의 조언
- 리팩터링과 기능 추가를 동시에 하지 말라
- 리팩터링을 시작하기 전 든든한 테스트가 있는지 먼저 확인하라. 할 수 있는 한 자주 테스트를 돌려 보라. 망가진 것을 빠르게 알아챌 수 있다.
- 단계를 작게 나누어서 신중하게 작업하라. 단계를 작게 나누고, 한 단계가 끝날 때마다 테스트를 돌린다면 기나긴 디버깅 작업을 피할 수 있다.
Comments