
한고원 데이터사전 Word2Vec README
13 Jul 2018 | word2vec
Word2Vec
본 코드들을 실행시키기 위해서는 tensorflow-gpu와 nltk설치가 필요합니다.
word2vec repository 내에는 11개의 코드가 존재합니다. 하지만 몇몇개의 코드는 특정 테스트를 위해 생성 된 것이므로, 이 Readme.md 에서는 6개의 코드에 대해서만 설명합니다.
word2vec_saram.pyword2vec_saram.shloadpickle.pyloadpickle.shfind_topk_sim.pyfind_topk_sim.sh
모든 코드는 python file과 shell script가 1:1 매칭되어 있습니다. 실행은 shell script로 실행하면 됩니다.
word2vec_saram.py
이 코드는 word2vec의 skip-gram 을 사용하여 word embedding을 수행하는 파이썬3 코드입니다.
본 코드는 크게 3가지 단계로 구성되어 있습니다.
- 데이터를 불러 온 후 Mini-batch화
- skip-gram 을 이용한 word embedding
- word vector visualization 및 결과 저장
skip gram의 세부 알고리즘에 대해서는 다음 논문 을 참고하시면 되겠습니다.
word2vec_saram.py 코드는 사람인 데이터를 기준으로 생성 된 코드 입니다만, input data 형식만 맞춰주면 어느 데이터를 사용하던 작동 할 수 있습니다. 다른 데이터를 사용하려면 line 82의 filename 변수를 주성 해 주시면 됩니다.
82 filename = 데이터의 디렉터리 위치
그리고 이 코드는 총 7개의 arguments를 입력 받습니다.
--log_dir : tensorboard log file과 visualization결과, 그리고 embedding table, dictionary등이 저장되는 위치 지정--embedding_size : word vector의 차원수 설정--batch_size : mini-batch size 설정--skip_window : 양 옆으로 몇개의 단어를 고려할지 설정--num_skips : 양 옆의 고려한 단어들 중에서 몇개를 정답과 맞추어 볼지 설정 (num_skips =< 2 * skip_window)--num_sampled : 중간 결과를 몇개를 볼 지--num_steps : training을 몇 step 만큼 지정 할 지
위 arguments는 word2vec_saram.sh에서 모두 지정되어 있습니다.
결과 image
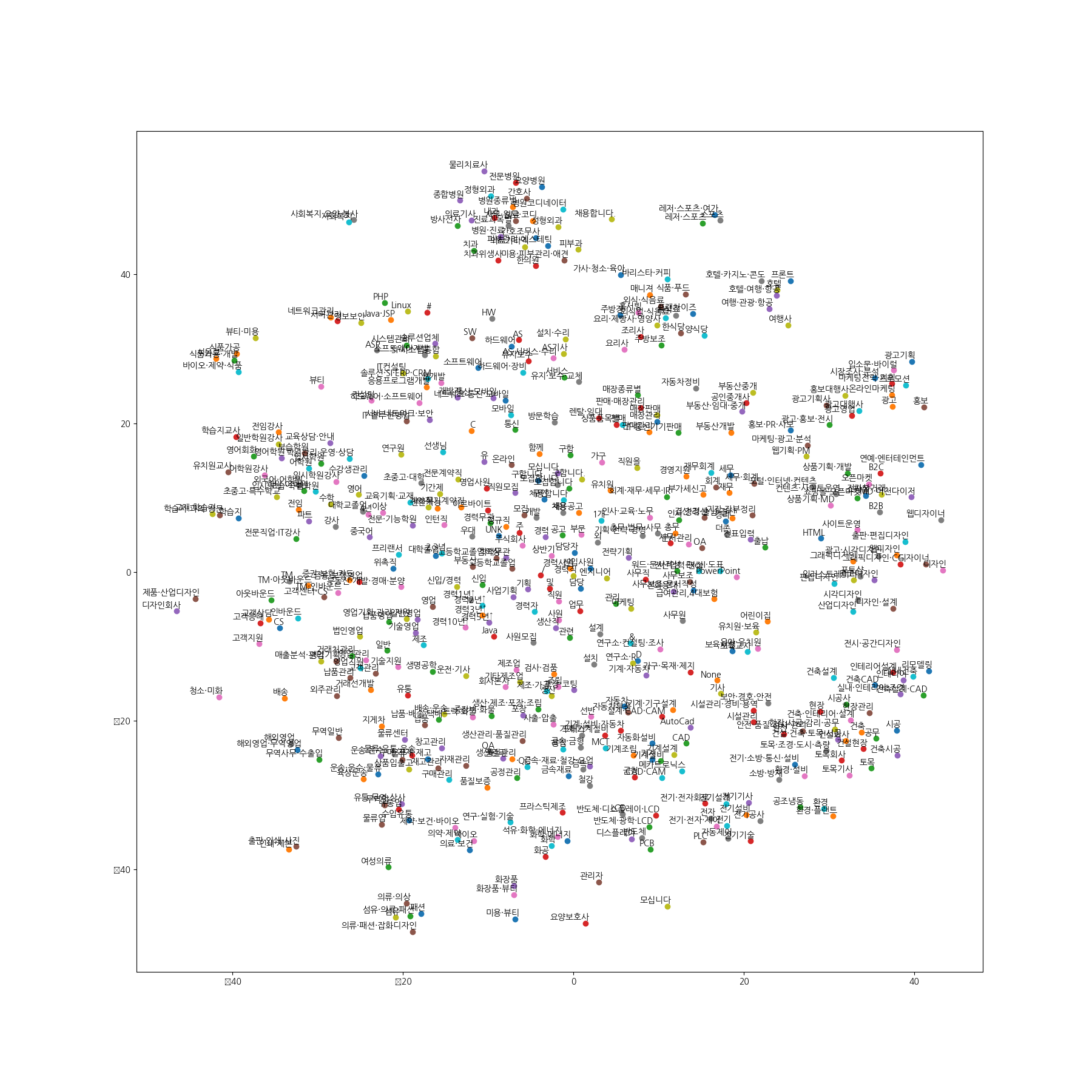
word2vec_saram.sh
실행방법:
sh word2vec_saram.sh
스크립트 내의 변수를 조정하여 word2vec 다양하게 실행 가능합니다.
loadpickle.py
word2vec_sarma.py에서 산출된 data.pkl, count.pkl, dictionary.pkl, reverse_dictionary.pkl, embedding.pkl 파일을 보는데 필요한 코드입니다.
이 코드 역시 실행은 loadpickle.sh로 하시면 됩니다.
arguments 목록:
--pkl_dir = pickle 파일이 존재하는 directory (보통 word2vec_saram.sh을 실행한 log_dir 위치를 입력)
loadpickle.sh
실행방법:
sh loadpickle.sh
find_topk_sim.py
word2vec_saram.py에서 산출 된 embedding.pkl, reverse_dictionary.pkl 파일을 이용하여 corpus에서 가장 많이 등장한 단어들의 가장 가까운 cosine similarity를 가진 단어를 출력해 줍니다.
argument:
--pkl_dir : pickle 파일이 존재하는 directory (보통 word2vec_saram.sh을 실행한 log_dir 위치를 입력)
find_topk_sim.sh
실행방법:
sh find_topk_sim.sh
visual_wordVec.py
word2vec_saram.py 에서 산출되는 visualization 부분을 떼어낸 코드
주의 : scikit learn 설치 필요합니다. 그리고 한글 폰트부분 에러 날 수 있습니다.
실행은 visual_wordVec.sh로 하면 됩니다.
visual_wordVec.py
스크립트 내에 embedding table, reverse dictionary, 결과 figure 이름(png 형식)을 바꾸어 가면서 실행가능
PLOT_ONLY의 경우 plot 내에 찍어주는 dot의 양 조절 가능
주의 : word2vec_saram.py에서는 visualization을 자동으로 해주지만…. 이 코드를 돌리기 위해서는 doc2vec이든 word2vec이든, 결과 embedding table과 reverse dictionary를 pickle 파일로 따로 저장이 되어있어야 합니다.
find_keyvalue.py
reverse_dictionary.pkl, embedding.pkl을 받아서 사용자가 지정한 단어와 가장 가까운 n개의 단어, cosine similiarity를 찾아주고, 다시 그 가까운 단어들의 가까운 n개의 단어와 cosine similiarity를 찾아서 namedtuple pickle, csv 파일로 저장해준다.
Word2Vec
본 코드들을 실행시키기 위해서는 tensorflow-gpu와 nltk설치가 필요합니다.
word2vec repository 내에는 11개의 코드가 존재합니다. 하지만 몇몇개의 코드는 특정 테스트를 위해 생성 된 것이므로, 이 Readme.md 에서는 6개의 코드에 대해서만 설명합니다.
word2vec_saram.pyword2vec_saram.shloadpickle.pyloadpickle.shfind_topk_sim.pyfind_topk_sim.sh
모든 코드는 python file과 shell script가 1:1 매칭되어 있습니다. 실행은 shell script로 실행하면 됩니다.
word2vec_saram.py
이 코드는 word2vec의 skip-gram 을 사용하여 word embedding을 수행하는 파이썬3 코드입니다. 본 코드는 크게 3가지 단계로 구성되어 있습니다.
- 데이터를 불러 온 후 Mini-batch화
- skip-gram 을 이용한 word embedding
- word vector visualization 및 결과 저장
skip gram의 세부 알고리즘에 대해서는 다음 논문 을 참고하시면 되겠습니다.
word2vec_saram.py 코드는 사람인 데이터를 기준으로 생성 된 코드 입니다만, input data 형식만 맞춰주면 어느 데이터를 사용하던 작동 할 수 있습니다. 다른 데이터를 사용하려면 line 82의 filename 변수를 주성 해 주시면 됩니다.
82 filename = 데이터의 디렉터리 위치
그리고 이 코드는 총 7개의 arguments를 입력 받습니다.
--log_dir: tensorboard log file과 visualization결과, 그리고 embedding table, dictionary등이 저장되는 위치 지정--embedding_size: word vector의 차원수 설정--batch_size: mini-batch size 설정--skip_window: 양 옆으로 몇개의 단어를 고려할지 설정--num_skips: 양 옆의 고려한 단어들 중에서 몇개를 정답과 맞추어 볼지 설정 (num_skips =< 2 * skip_window)--num_sampled: 중간 결과를 몇개를 볼 지--num_steps: training을 몇 step 만큼 지정 할 지
위 arguments는 word2vec_saram.sh에서 모두 지정되어 있습니다.
결과 image
word2vec_saram.sh
실행방법:
sh word2vec_saram.sh
스크립트 내의 변수를 조정하여 word2vec 다양하게 실행 가능합니다.
loadpickle.py
word2vec_sarma.py에서 산출된 data.pkl, count.pkl, dictionary.pkl, reverse_dictionary.pkl, embedding.pkl 파일을 보는데 필요한 코드입니다.
이 코드 역시 실행은 loadpickle.sh로 하시면 됩니다.
arguments 목록:
--pkl_dir= pickle 파일이 존재하는 directory (보통word2vec_saram.sh을 실행한 log_dir 위치를 입력)
loadpickle.sh
실행방법:
sh loadpickle.sh
find_topk_sim.py
word2vec_saram.py에서 산출 된 embedding.pkl, reverse_dictionary.pkl 파일을 이용하여 corpus에서 가장 많이 등장한 단어들의 가장 가까운 cosine similarity를 가진 단어를 출력해 줍니다.
argument:
--pkl_dir: pickle 파일이 존재하는 directory (보통word2vec_saram.sh을 실행한 log_dir 위치를 입력)
find_topk_sim.sh
실행방법:
sh find_topk_sim.sh
visual_wordVec.py
word2vec_saram.py 에서 산출되는 visualization 부분을 떼어낸 코드
주의 : scikit learn 설치 필요합니다. 그리고 한글 폰트부분 에러 날 수 있습니다.
실행은 visual_wordVec.sh로 하면 됩니다.
visual_wordVec.py
스크립트 내에 embedding table, reverse dictionary, 결과 figure 이름(png 형식)을 바꾸어 가면서 실행가능 PLOT_ONLY의 경우 plot 내에 찍어주는 dot의 양 조절 가능
주의 : word2vec_saram.py에서는 visualization을 자동으로 해주지만…. 이 코드를 돌리기 위해서는 doc2vec이든 word2vec이든, 결과 embedding table과 reverse dictionary를 pickle 파일로 따로 저장이 되어있어야 합니다.
find_keyvalue.py
reverse_dictionary.pkl, embedding.pkl을 받아서 사용자가 지정한 단어와 가장 가까운 n개의 단어, cosine similiarity를 찾아주고, 다시 그 가까운 단어들의 가까운 n개의 단어와 cosine similiarity를 찾아서 namedtuple pickle, csv 파일로 저장해준다.
Comments