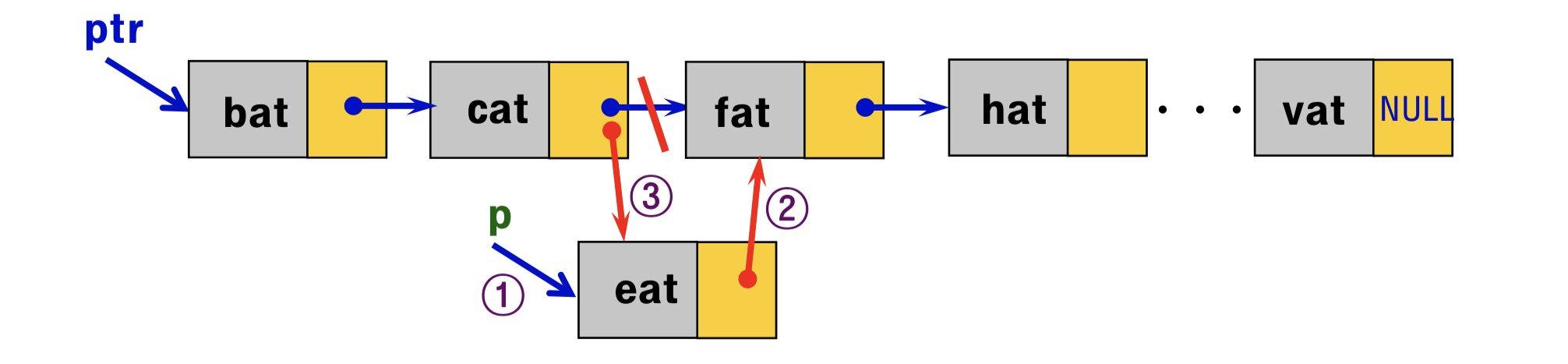
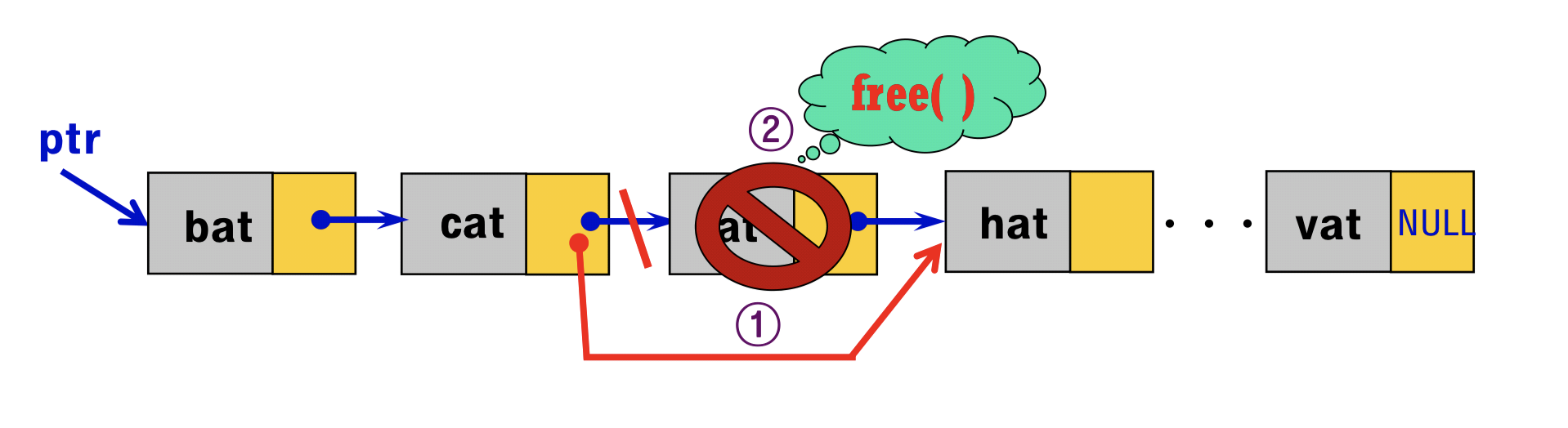
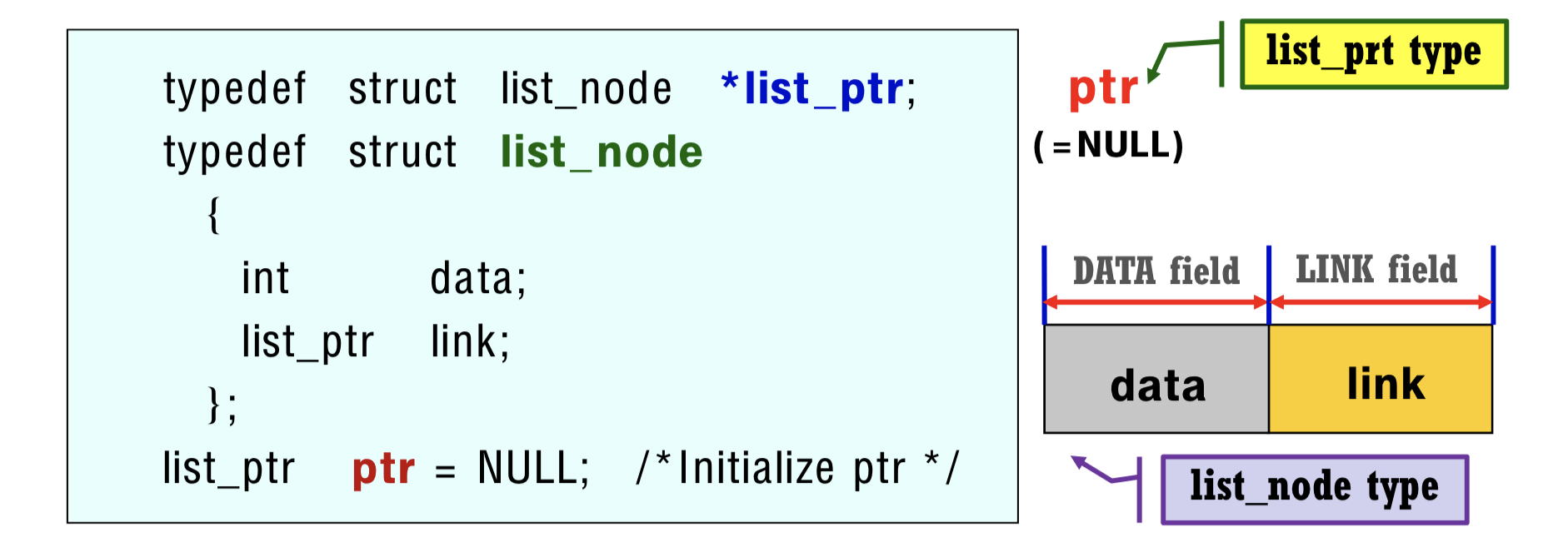
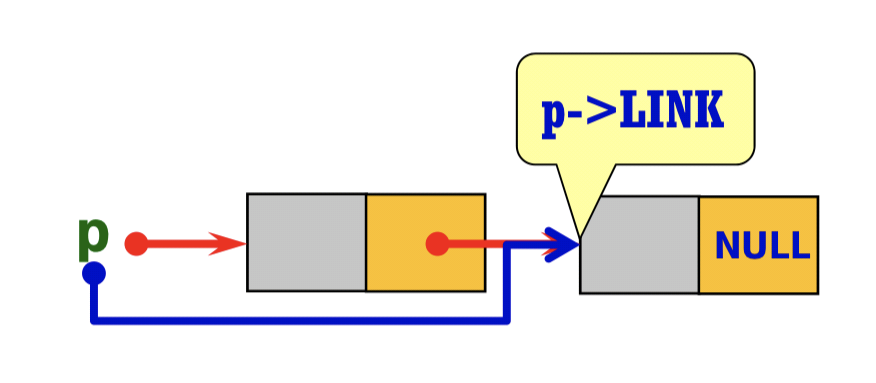
C++ 더 쉽고, 더 깊게 - chap 11. 구조체
07 Nov 2018 | study C++
Chapter 11. 구조체
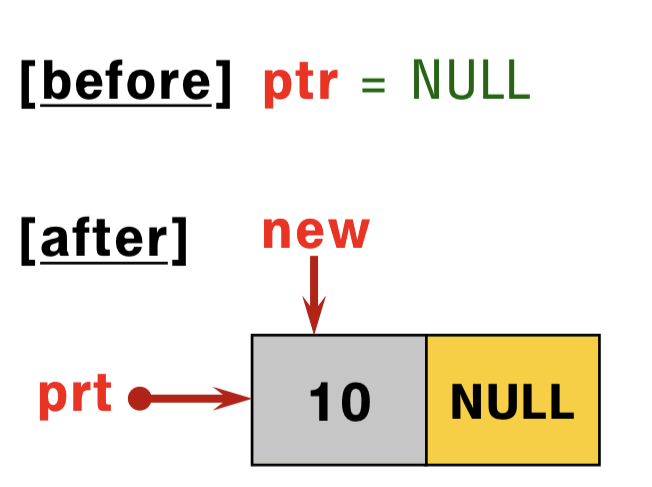
여러값을 하나로 묶기
- 지금까지는 한 종류의 값 (ex. int, float…)을 배열(array)에 저장
- 하지만 처리할 데이터가 많아지면 서로 연관된 데이터를 다루어야 할 때도 많아짐
- 예를들어, 비디오 게임에서는 플레이어의 이름뿐만 아니라 와편 좌표 (x, y) 도 저장 해야 함. 이를 기존 방식으로 생각하면
int x_coordinates[ 10 ];
int y_coordinates[ 10 ];
string names[ 10 ];
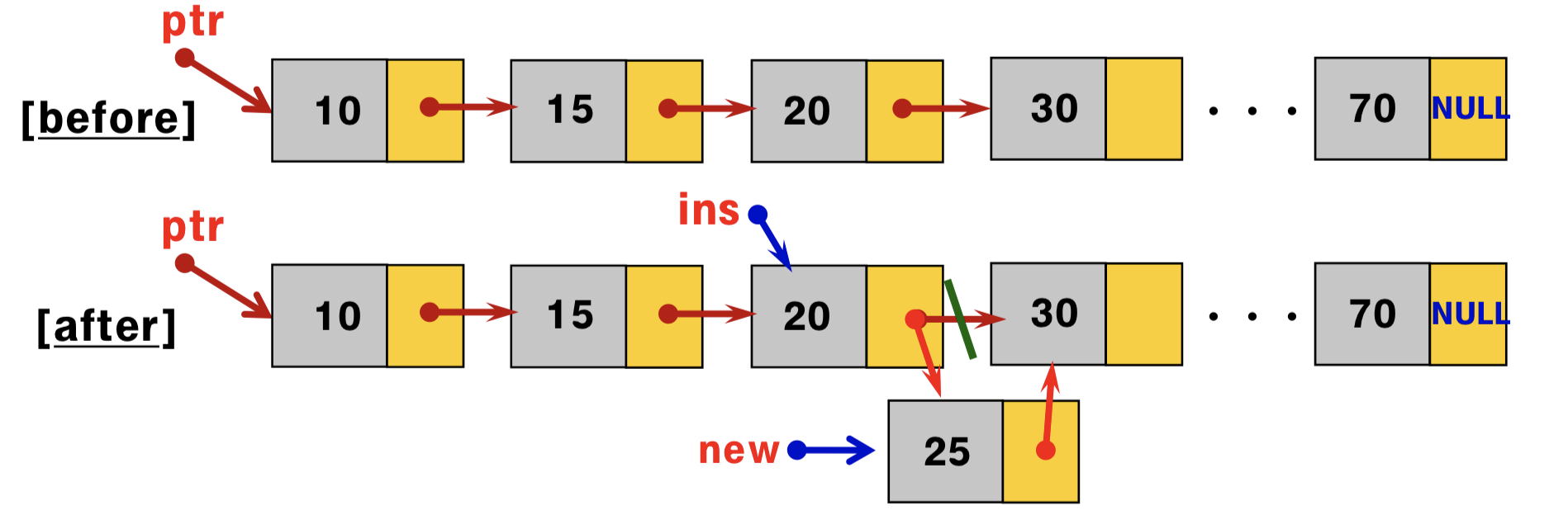
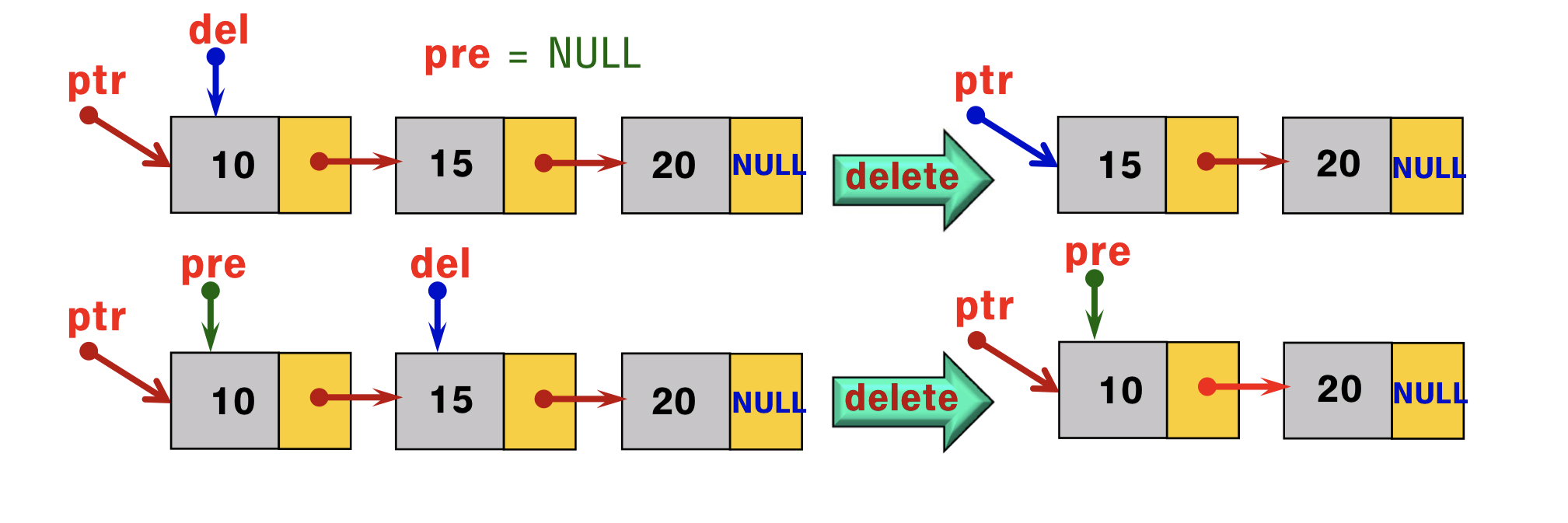
- 하지만 이 세 배열은 서로 짝을 이루고 있으므로, 어느 한 배열에서 요소의 위치를 옮기면 다른 두 배열에서 이와 연관된 요소도 함께 옮겨야 함 (ex. sort)
- 만약 네 번째 값을 추적해야 한다면 상당히 어려워짐 (ex. HP gage).
- 네 번째 배열 추가
- 처음의 세 배열과 동기화
- 요런 귀찮을거 막기위해 구조체가 있다!
- 여러 데이터를 한데 모아야 할 때 유용
###문법
- 구조체를 정의하기 위한 문법은 다음과 같다
struct SpaceShip
{
int x_coordinate;
int y_coordinate;
string name;
};
- 여기서 ShapeShip은 구조체라는 특별한 타입의 이름이다.
- 기존의 int나 double처럼 우리가 직접 타입을 만든 것
- 다음과 같이 선언 가능
SpaceShip my_ship;
my_ship.x_coordinate = 40;
my_ship.y_coordinate = 40;
my_ship.name = "USS Enterprise (NCC-1701-D)";
-
x_coordinate, y_coordinate, name은 새로 만들어진 타입의 필드다
-
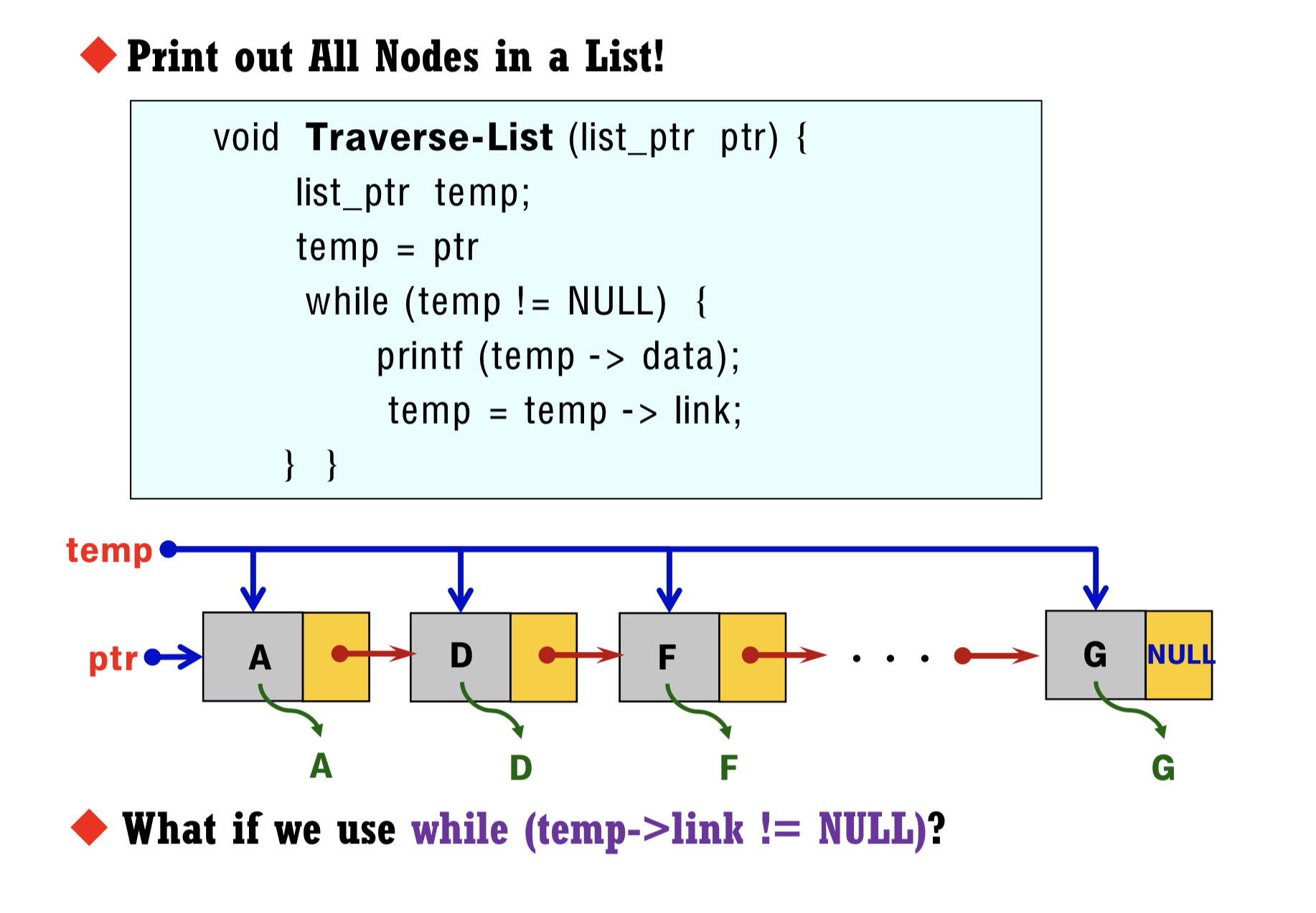
다음의 예시 프로그램은 다섯 명의 플레이어의 이름을 읽는 프로그램인데, 게임자체는 포함되지 않으며, 배열과 구조체가 함께 사용
#include <iostream>
using namespace std;
struct PlayerInfo
{
int skill_level;
string name;
};
int main()
{
// 일반적인 변수 타입처럼 구조체도 배열로 만들 수 있다.
PlayerInfo players[ 5 ];
for ( int i = 0; i < 5; i++ )
{
cout << "Please enter the name for player : "
<< i << endl;
// 우선 일반적인 배열 문법으로 배열의 요소에 접근한 다음,
// '.' 문법으로 구조체의 필드에 접근
cin >> players[ i ].name;
cout << "Please enter the skill level for "
<< players[ i ].name << endl;
cin >> players[ i ].skill_level;
}
for ( int i = 0; i < 5; ++i)
{
cout << players[ i ].name
<< " is at skill level "
<< players[ i ].skill_level << endl;
}
}
- PlayerInfo 구조체에서는 두 가지 필드를 선언
- 플레이어의 이름
- 플레이어의 skill_level
- PlayerInfo를 여느 변수 처럼(ex.
int) 사용할 수 있으므로, 플레이어들의 배열을 만들수도 있음
- 구조체로 배열을 만들면 배열의 각 요소를 구조체의 인스턴스처럼 다룰 수 있음
- 배열에서 첮 번째 구조체의 필드는 배열의 첫 번째 요소에서 플레이어의 이름에 해당
players[ 0 ].name으로 접근 가능
- 이 프로그램에서는 다섯 명의 플레이어 정보를 읽어 들이기 위한 배열과 구조체를 두 종류의 데이터와 하나의 루프로 결합한 다음, 두 번째 루프에서 이 정보를 표시할 수 있는 능력을 적극 활용
- 데이터를 처리하기 위한 배열을 따로 둘 이유도 없고, player_names와 player_skill_level 배열도 따로 둘 이유가 없음
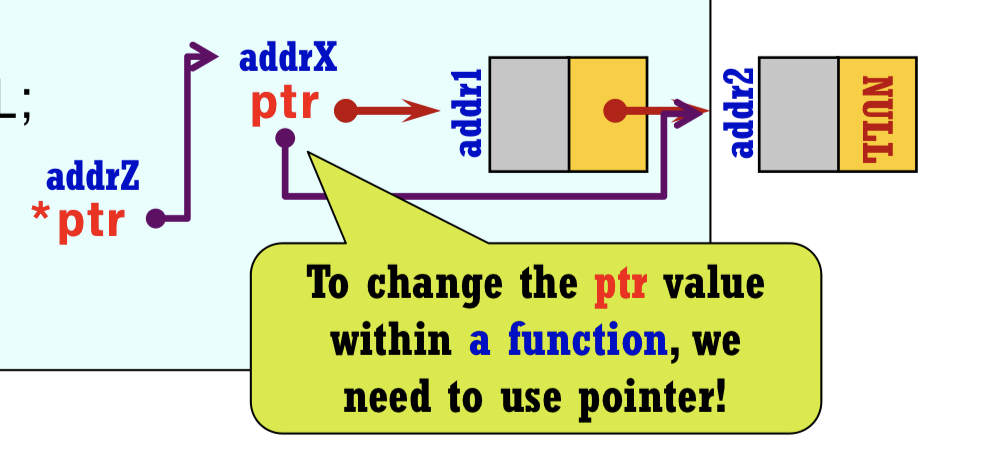
구조체 전달하기
- 구조체를 인수로 받거나 리턴하는 함수를 작성해야 할 때가 있음
- ex. 우주선을 조작하는 게임에서 새로운 적에 해당하는 구조체를 초기화 해보자
```cpp
struc Enemy
Chapter 11. 구조체
여러값을 하나로 묶기
- 지금까지는 한 종류의 값 (ex. int, float…)을 배열(array)에 저장
- 하지만 처리할 데이터가 많아지면 서로 연관된 데이터를 다루어야 할 때도 많아짐
- 예를들어, 비디오 게임에서는 플레이어의 이름뿐만 아니라 와편 좌표 (x, y) 도 저장 해야 함. 이를 기존 방식으로 생각하면
int x_coordinates[ 10 ]; int y_coordinates[ 10 ]; string names[ 10 ]; - 하지만 이 세 배열은 서로 짝을 이루고 있으므로, 어느 한 배열에서 요소의 위치를 옮기면 다른 두 배열에서 이와 연관된 요소도 함께 옮겨야 함 (ex. sort)
- 만약 네 번째 값을 추적해야 한다면 상당히 어려워짐 (ex. HP gage).
- 네 번째 배열 추가
- 처음의 세 배열과 동기화
- 요런 귀찮을거 막기위해 구조체가 있다!
- 여러 데이터를 한데 모아야 할 때 유용
###문법
- 구조체를 정의하기 위한 문법은 다음과 같다
struct SpaceShip { int x_coordinate; int y_coordinate; string name; }; - 여기서 ShapeShip은 구조체라는 특별한 타입의 이름이다.
- 기존의 int나 double처럼 우리가 직접 타입을 만든 것
- 다음과 같이 선언 가능
SpaceShip my_ship;
my_ship.x_coordinate = 40;
my_ship.y_coordinate = 40;
my_ship.name = "USS Enterprise (NCC-1701-D)";
-
x_coordinate,y_coordinate,name은 새로 만들어진 타입의 필드다 -
다음의 예시 프로그램은 다섯 명의 플레이어의 이름을 읽는 프로그램인데, 게임자체는 포함되지 않으며, 배열과 구조체가 함께 사용
#include <iostream>
using namespace std;
struct PlayerInfo
{
int skill_level;
string name;
};
int main()
{
// 일반적인 변수 타입처럼 구조체도 배열로 만들 수 있다.
PlayerInfo players[ 5 ];
for ( int i = 0; i < 5; i++ )
{
cout << "Please enter the name for player : "
<< i << endl;
// 우선 일반적인 배열 문법으로 배열의 요소에 접근한 다음,
// '.' 문법으로 구조체의 필드에 접근
cin >> players[ i ].name;
cout << "Please enter the skill level for "
<< players[ i ].name << endl;
cin >> players[ i ].skill_level;
}
for ( int i = 0; i < 5; ++i)
{
cout << players[ i ].name
<< " is at skill level "
<< players[ i ].skill_level << endl;
}
}
- PlayerInfo 구조체에서는 두 가지 필드를 선언
- 플레이어의 이름
- 플레이어의 skill_level
- PlayerInfo를 여느 변수 처럼(ex.
int) 사용할 수 있으므로, 플레이어들의 배열을 만들수도 있음- 구조체로 배열을 만들면 배열의 각 요소를 구조체의 인스턴스처럼 다룰 수 있음
- 배열에서 첮 번째 구조체의 필드는 배열의 첫 번째 요소에서 플레이어의 이름에 해당
players[ 0 ].name으로 접근 가능
- 이 프로그램에서는 다섯 명의 플레이어 정보를 읽어 들이기 위한 배열과 구조체를 두 종류의 데이터와 하나의 루프로 결합한 다음, 두 번째 루프에서 이 정보를 표시할 수 있는 능력을 적극 활용
- 데이터를 처리하기 위한 배열을 따로 둘 이유도 없고, player_names와 player_skill_level 배열도 따로 둘 이유가 없음
구조체 전달하기
- 구조체를 인수로 받거나 리턴하는 함수를 작성해야 할 때가 있음
- ex. 우주선을 조작하는 게임에서 새로운 적에 해당하는 구조체를 초기화 해보자
```cpp struc Enemy